\n
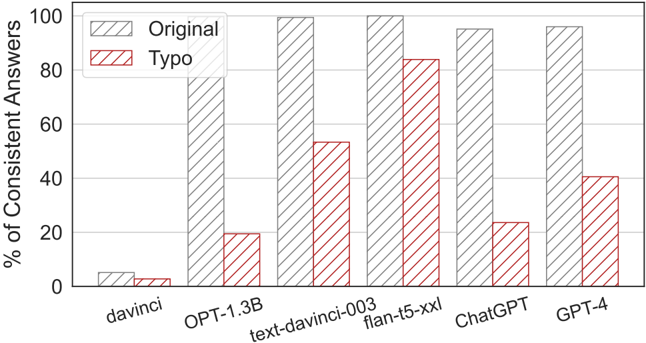
## Bar Chart: Consistency of Answers with and without Typos
### Overview
This bar chart compares the percentage of consistent answers from several language models (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4) when presented with questions containing typos versus original questions. Each model has two bars representing its performance with original questions and questions with typos. The y-axis represents the percentage of consistent answers, ranging from 0 to 100.
### Components/Axes
* **X-axis:** Language Models - davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4
* **Y-axis:** % of Consistent Answers (Scale: 0 to 100)
* **Legend:**
* Original (Light Gray)
* Typo (Red)
### Detailed Analysis
The chart consists of six groups of bars, one for each language model. Within each group, there's a light gray bar representing the "Original" condition and a red bar representing the "Typo" condition.
* **davinci:**
* Original: Approximately 8% (± 2%)
* Typo: Approximately 10% (± 2%)
* **OPT-1.3B:**
* Original: Approximately 98% (± 2%)
* Typo: Approximately 20% (± 2%)
* **text-davinci-003:**
* Original: Approximately 99% (± 2%)
* Typo: Approximately 52% (± 2%)
* **flan-t5-xxl:**
* Original: Approximately 99% (± 2%)
* Typo: Approximately 85% (± 2%)
* **ChatGPT:**
* Original: Approximately 95% (± 2%)
* Typo: Approximately 25% (± 2%)
* **GPT-4:**
* Original: Approximately 98% (± 2%)
* Typo: Approximately 42% (± 2%)
The "Original" bars are consistently high, generally above 90%, except for davinci which is around 8%. The "Typo" bars show a significant drop in performance for all models, with values ranging from approximately 10% (davinci) to 85% (flan-t5-xxl).
### Key Observations
* The performance of all models is significantly reduced when presented with questions containing typos.
* davinci is particularly sensitive to typos, showing a large drop in consistent answers.
* flan-t5-xxl demonstrates the highest robustness to typos, maintaining a relatively high percentage of consistent answers even with typos present.
* OPT-1.3B, text-davinci-003, and GPT-4 show a substantial decrease in performance when typos are introduced.
* ChatGPT's performance with typos is lower than flan-t5-xxl, but higher than davinci, text-davinci-003, and OPT-1.3B.
### Interpretation
The data suggests that the ability of language models to provide consistent answers is highly dependent on the quality of the input. Typos significantly disrupt the models' performance, indicating a lack of robustness to noisy input. The varying degrees of sensitivity to typos across different models suggest differences in their underlying architectures and training data.
flan-t5-xxl's relative resilience to typos could be attributed to its training methodology, potentially including a larger proportion of noisy or imperfect data. davinci's extreme sensitivity suggests it may rely more heavily on exact string matching or have a less robust understanding of semantic meaning.
The consistent high performance on "Original" questions indicates that these models are generally capable of providing consistent answers when presented with well-formed input. However, the substantial drop in performance with typos highlights a critical limitation in real-world applications where input is often imperfect. This data underscores the importance of input validation and error correction in systems that rely on these language models.