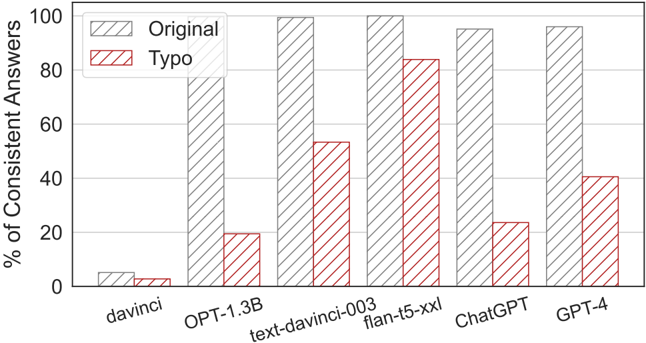
## Bar Chart: Comparison of Consistent Answers Between Original and Typo Models
### Overview
The chart compares the percentage of consistent answers between two model variants ("Original" and "Typo") across six AI systems: davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4. The "Original" model consistently outperforms the "Typo" variant across all systems, with the largest gap observed in smaller models like davinci and OPT-1.3B.
### Components/Axes
- **X-axis**: AI model names (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4)
- **Y-axis**: "% of Consistent Answers" (0–100% scale)
- **Legend**:
- **Original**: Gray bars with diagonal stripes (top-left placement)
- **Typo**: Red bars with diagonal stripes (top-left placement)
- **Bar Groups**: Each AI model has two adjacent bars (Original and Typo)
### Detailed Analysis
1. **davinci**:
- Original: ~5% (gray)
- Typo: ~2% (red)
- *Note*: Both values are near the bottom of the y-axis, indicating minimal consistency.
2. **OPT-1.3B**:
- Original: ~95% (gray)
- Typo: ~20% (red)
- *Note*: Largest performance gap between variants (~75% difference).
3. **text-davinci-003**:
- Original: ~95% (gray)
- Typo: ~55% (red)
- *Note*: Typo retains ~60% of Original's performance.
4. **flan-t5-xxl**:
- Original: ~95% (gray)
- Typo: ~85% (red)
- *Note*: Smallest performance gap (~10% difference), suggesting Typo performs relatively better in larger models.
5. **ChatGPT**:
- Original: ~90% (gray)
- Typo: ~25% (red)
- *Note*: Typo drops to ~28% of Original's performance.
6. **GPT-4**:
- Original: ~95% (gray)
- Typo: ~40% (red)
- *Note*: Typo achieves ~42% of Original's performance.
### Key Observations
- **Consistency Trend**: Original models maintain >90% consistency across all systems, while Typo models range from 2% (davinci) to 85% (flan-t5-xxl).
- **Model Size Correlation**: Larger models (flan-t5-xxl, GPT-4) show smaller performance gaps between Original and Typo variants.
- **Outlier**: The davinci model exhibits the lowest consistency for both variants, with Typo performing only 40% as well as Original.
### Interpretation
The data suggests that model architecture or training data significantly impacts consistency, with Original variants demonstrating robust performance across all systems. The reduced performance gap in larger models (flan-t5-xxl, GPT-4) implies that scale may mitigate the effects of typographical errors. However, the stark drop in smaller models (davinci, OPT-1.3B) highlights potential vulnerabilities in handling input variations. This could inform deployment decisions: larger models may be preferable for tasks requiring high consistency despite typos, while smaller models might require preprocessing to clean inputs.