## Bar Chart: E-CARE: Avg. Concept Drift
### Overview
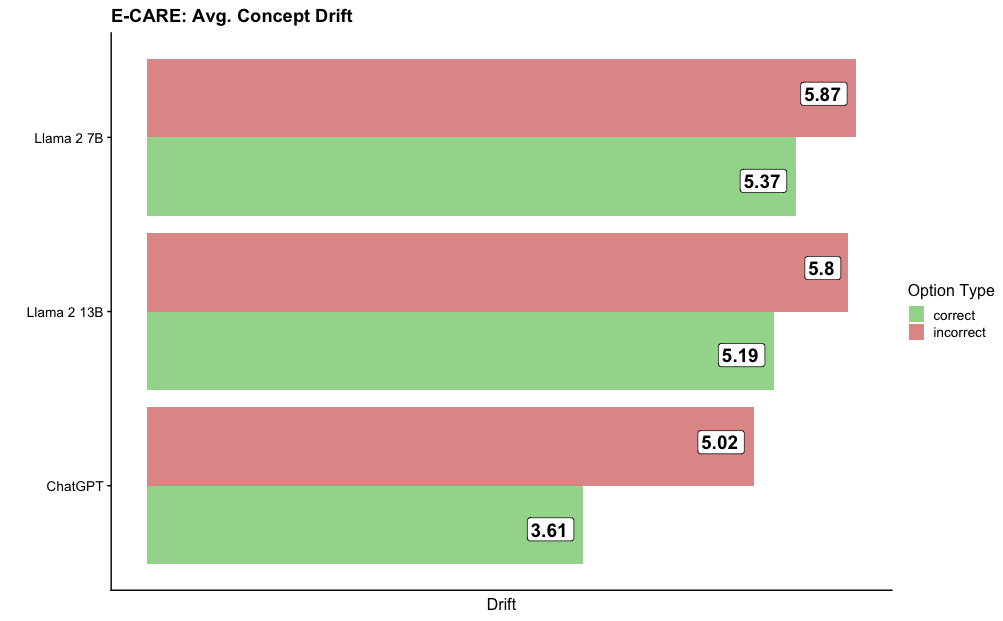
The image is a horizontal bar chart comparing the average concept drift of three language models (ChatGPT, Llama 2 13B, and Llama 2 7B) based on whether the model's response was correct or incorrect. The chart displays two bars for each model, one representing the average drift when the response was correct (green) and the other when the response was incorrect (red).
### Components/Axes
* **Title:** E-CARE: Avg. Concept Drift
* **Y-axis:** Model Names (ChatGPT, Llama 2 13B, Llama 2 7B)
* **X-axis:** Drift
* **Legend (Top-Right):**
* Correct (Green)
* Incorrect (Red)
### Detailed Analysis
The chart presents the average concept drift for each model under two conditions: when the model's response is correct and when it is incorrect. The drift values are displayed at the end of each bar.
* **ChatGPT:**
* Correct (Green): 3.61
* Incorrect (Red): 5.02
* **Llama 2 13B:**
* Correct (Green): 5.19
* Incorrect (Red): 5.80
* **Llama 2 7B:**
* Correct (Green): 5.37
* Incorrect (Red): 5.87
### Key Observations
* For all three models, the average concept drift is higher when the response is incorrect compared to when it is correct.
* ChatGPT has the lowest drift when the response is correct (3.61), but also the largest difference between correct and incorrect responses (5.02 - 3.61 = 1.41).
* Llama 2 7B has the highest drift when the response is incorrect (5.87).
* The Llama 2 models have a smaller difference in drift between correct and incorrect responses compared to ChatGPT.
### Interpretation
The data suggests that all three language models exhibit a higher concept drift when they provide incorrect responses. This could indicate that errors are associated with a greater degree of deviation from the intended or expected concept. ChatGPT, while having the lowest drift for correct answers, shows the most significant increase in drift when it makes mistakes, suggesting its errors might be more conceptually divergent. The Llama 2 models show a more consistent level of drift regardless of the correctness of the response. This information is valuable for understanding the behavior of these models and identifying areas for improvement in their training or application.