\n
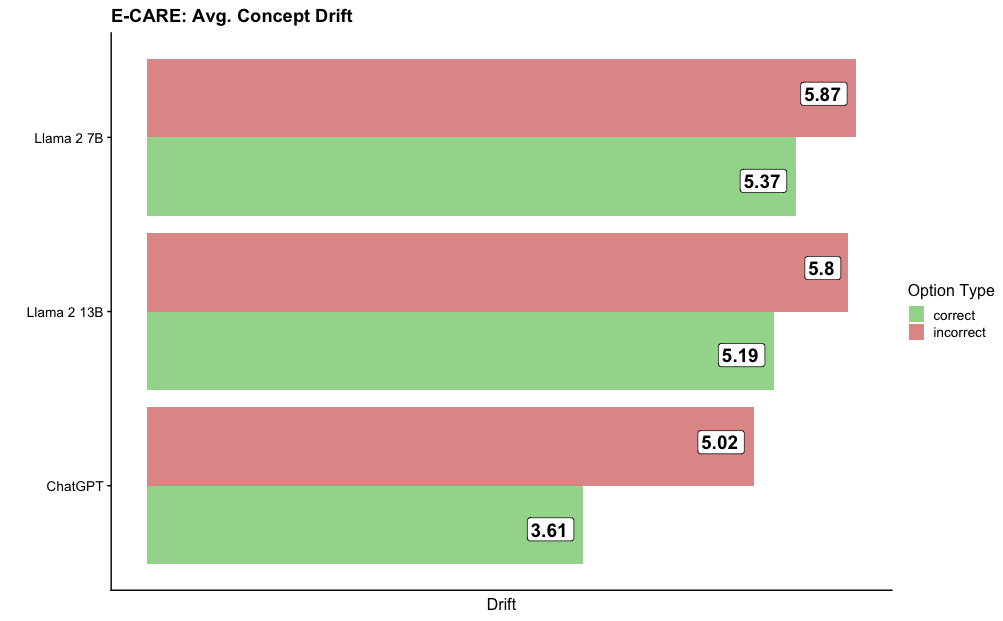
## Horizontal Bar Chart: E-CARE: Avg. Concept Drift
### Overview
This is a horizontal bar chart comparing the average concept drift for three different language models: Llama 2 7B, Llama 2 13B, and ChatGPT. The chart displays the average drift for both correct and incorrect options. The x-axis represents the "Drift" value, and the y-axis lists the language models.
### Components/Axes
* **Title:** E-CARE: Avg. Concept Drift
* **X-axis Label:** Drift (no units specified)
* **Y-axis Labels:** Llama 2 7B, Llama 2 13B, ChatGPT
* **Legend:**
* **Label:** Option Type
* **Correct:** Represented by green bars.
* **Incorrect:** Represented by red/brown bars.
### Detailed Analysis
The chart consists of six horizontal bars, grouped by language model. Each model has two bars representing the average drift for correct and incorrect options.
* **Llama 2 7B:**
* Incorrect Drift: Approximately 5.87 (red/brown bar)
* Correct Drift: Approximately 5.37 (green bar)
* **Llama 2 13B:**
* Incorrect Drift: Approximately 5.8 (red/brown bar)
* Correct Drift: Approximately 5.19 (green bar)
* **ChatGPT:**
* Incorrect Drift: Approximately 5.02 (red/brown bar)
* Correct Drift: Approximately 3.61 (green bar)
The incorrect drift values are consistently higher than the correct drift values for each model.
### Key Observations
* ChatGPT exhibits the lowest average drift for correct options (3.61), significantly lower than Llama 2 7B (5.37) and Llama 2 13B (5.19).
* The difference between correct and incorrect drift is most pronounced for ChatGPT (5.02 - 3.61 = 1.41).
* Llama 2 7B and Llama 2 13B have very similar drift values for both correct and incorrect options.
* The incorrect drift values for Llama 2 7B and Llama 2 13B are nearly identical (5.87 and 5.8 respectively).
### Interpretation
The chart suggests that ChatGPT is more consistent in its responses, exhibiting less concept drift when providing correct answers compared to Llama 2 7B and Llama 2 13B. The larger difference between correct and incorrect drift for ChatGPT indicates that it is better at identifying and avoiding conceptual errors. The similarity in drift values between the two Llama 2 models suggests they perform similarly in this E-CARE task. The "Drift" metric likely represents a measure of how much the model's understanding or response deviates from the expected or correct concept. A higher drift value indicates a greater deviation. The data suggests that while all models exhibit some degree of concept drift, ChatGPT demonstrates a stronger ability to maintain conceptual consistency, particularly when generating correct responses. The E-CARE task is not defined, but it appears to be a benchmark for evaluating the conceptual understanding of language models.