## Bar Chart: E-CARE: Avg. Concept Drift
### Overview
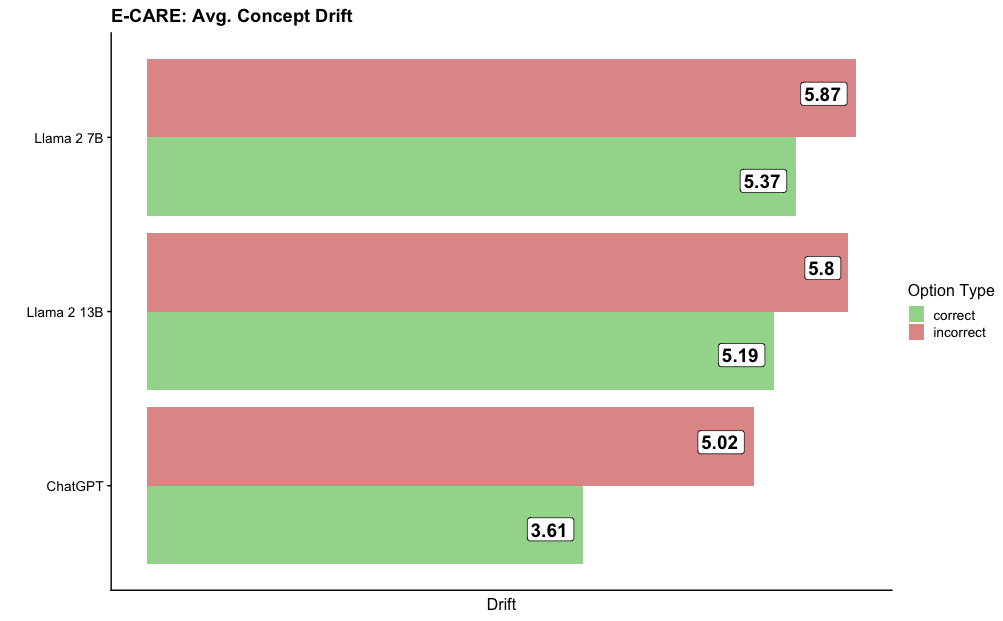
The chart compares average concept drift values for three AI models (Llama 2 7B, Llama 2 13B, and ChatGPT) across two option types: "correct" (green) and "incorrect" (red). Values represent drift magnitudes, with higher numbers indicating greater deviation from baseline performance.
### Components/Axes
- **Vertical Axis (Categories)**:
- Models: Llama 2 7B, Llama 2 13B, ChatGPT (listed top to bottom)
- **Horizontal Axis (Values)**:
- Labeled "Drift" with no explicit scale, but values range from ~3.6 to 5.87
- **Legend**:
- Right-aligned, associates:
- Green = "correct" option type
- Red = "incorrect" option type
- **Bars**:
- Grouped horizontally for each model, with numerical labels inside bars
### Detailed Analysis
1. **Llama 2 7B**:
- Correct: 5.37 (green bar)
- Incorrect: 5.87 (red bar)
2. **Llama 2 13B**:
- Correct: 5.19 (green bar)
- Incorrect: 5.8 (red bar)
3. **ChatGPT**:
- Correct: 3.61 (green bar)
- Incorrect: 5.02 (red bar)
### Key Observations
- **Inverse Relationship**: For all models, "incorrect" drift values exceed "correct" drift values, suggesting models are more sensitive to drift in incorrect options.
- **Model Performance**:
- Llama 2 7B shows the highest overall drift (5.87 incorrect).
- ChatGPT has the lowest correct drift (3.61) but still exhibits higher incorrect drift (5.02).
- **Scale Consistency**: All values cluster between 3.6 and 5.9, indicating relatively similar drift magnitudes across models.
### Interpretation
The data suggests that AI models exhibit greater performance degradation when evaluating incorrect options compared to correct ones under concept drift. Llama 2 7B demonstrates the most pronounced vulnerability to drift in incorrect options, while ChatGPT maintains the lowest correct drift but still suffers from significant incorrect drift. This pattern may reflect architectural differences in handling ambiguity or error tolerance. The consistent trend across models highlights a potential systemic challenge in maintaining accuracy under evolving data conditions.