\n
## Diagram: Neural Network Architecture
### Overview
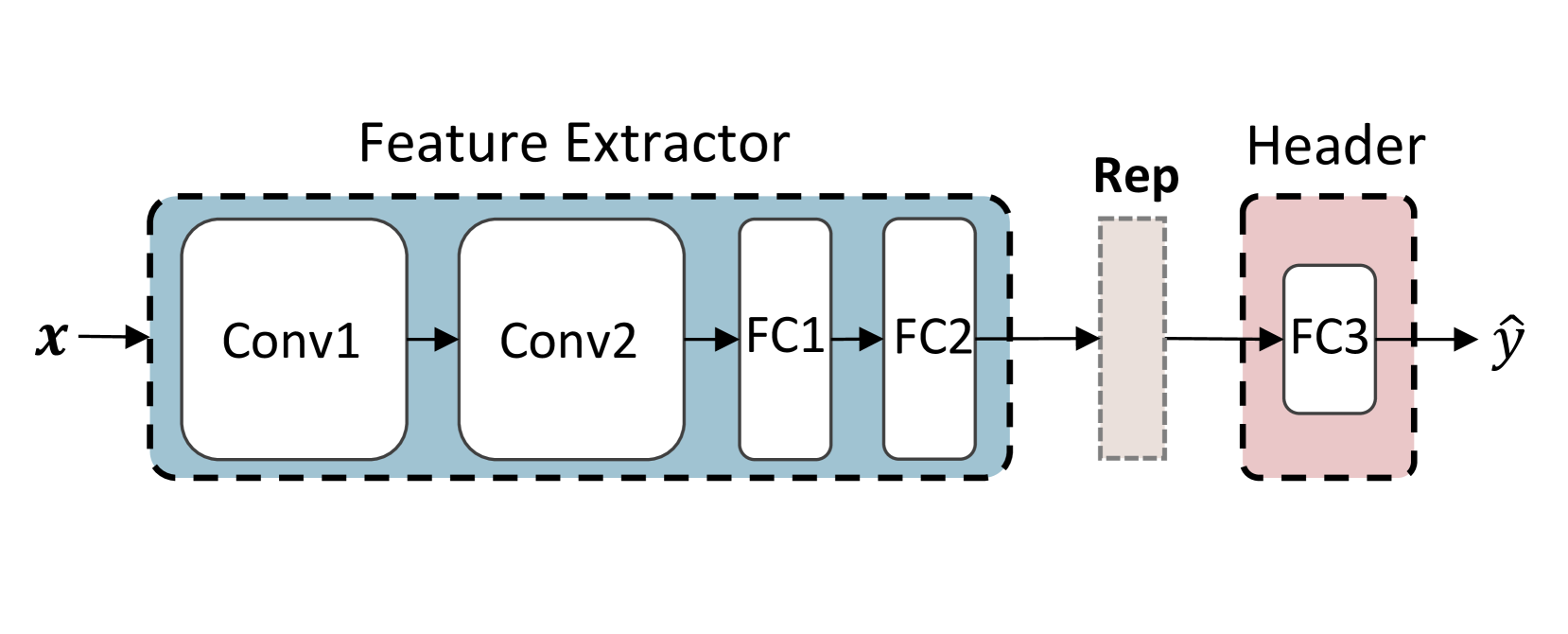
The image depicts a simplified neural network architecture, specifically a feature extractor followed by a header (classification) component. The diagram illustrates the flow of data from input 'x' to output 'ŷ' through a series of convolutional and fully connected layers.
### Components/Axes
The diagram consists of two main blocks: "Feature Extractor" and "Header".
- **Feature Extractor:** Contains four sequential layers: Conv1, Conv2, FC1, and FC2.
- **Header:** Contains a single fully connected layer: FC3.
- **Input:** 'x'
- **Output:** 'ŷ'
- **Intermediate Representation:** "Rep"
- The diagram uses arrows to indicate the direction of data flow.
- Dashed boxes enclose the Feature Extractor and Header blocks.
### Detailed Analysis or Content Details
The diagram shows a sequential data flow:
1. Input 'x' enters the "Feature Extractor".
2. 'x' is processed by Conv1, then Conv2.
3. The output of Conv2 is fed into FC1, followed by FC2.
4. The output of FC2 is labeled as "Rep" (Representation).
5. "Rep" is then passed to the "Header".
6. The "Header" consists of a single layer, FC3, which produces the output 'ŷ'.
The layers are represented as rectangular blocks. The connections between layers are indicated by arrows. The "Feature Extractor" block is enclosed in a larger dashed box, and the "Header" block is enclosed in a smaller dashed box. The "Rep" label is positioned between the "Feature Extractor" and "Header" blocks, indicating an intermediate representation of the input data.
### Key Observations
The diagram illustrates a common pattern in neural network design: a feature extraction stage followed by a classification or regression stage. The use of convolutional layers (Conv1, Conv2) suggests that the network is designed to process image or other grid-like data. The fully connected layers (FC1, FC2, FC3) are used to map the extracted features to the final output.
### Interpretation
This diagram represents a basic convolutional neural network (CNN) architecture. The "Feature Extractor" learns hierarchical representations of the input data through convolutional and fully connected layers. The "Header" then uses these learned features to make a prediction (ŷ). The intermediate representation "Rep" captures the essential features extracted from the input. This architecture is commonly used for image classification, object detection, and other computer vision tasks. The diagram is a high-level overview and does not specify details such as the number of filters in the convolutional layers, the number of neurons in the fully connected layers, or the activation functions used. It is a conceptual illustration of the network's structure and data flow.