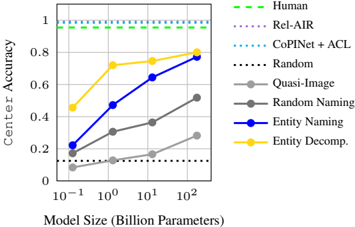
## Line Graph: Center Accuracy vs. Model Size
### Overview
The graph illustrates the relationship between model size (in billion parameters) and center accuracy across various models. It compares human performance, state-of-the-art models (Rel-AIR, CoPINet + ACL), and baseline models (Random, Quasi-Image, Random Naming, Entity Naming, Entity Decomp.). The y-axis represents accuracy (0–1), while the x-axis spans model sizes from 0.1B to 100B parameters.
### Components/Axes
- **X-axis**: Model Size (Billion Parameters) – Logarithmic scale (10⁻¹ to 10²).
- **Y-axis**: Center Accuracy – Linear scale (0 to 1).
- **Legend**:
- Human (dashed green line)
- Rel-AIR (dotted purple line)
- CoPINet + ACL (dotted blue line)
- Random (black dotted line)
- Quasi-Image (gray solid line)
- Random Naming (gray dashed line)
- Entity Naming (blue solid line)
- Entity Decomp. (orange solid line)
### Detailed Analysis
1. **Human Performance**:
- Dashed green line remains flat at ~0.95 accuracy across all model sizes.
2. **Rel-AIR**:
- Dotted purple line stays flat at ~0.9 accuracy.
3. **CoPINet + ACL**:
- Dotted blue line remains flat at ~0.85 accuracy.
4. **Random Baseline**:
- Black dotted line stays flat at ~0.1 accuracy.
5. **Quasi-Image**:
- Gray solid line starts at ~0.1 (0.1B) and increases to ~0.3 (100B).
6. **Random Naming**:
- Gray dashed line starts at ~0.15 (0.1B) and rises to ~0.5 (100B).
7. **Entity Naming**:
- Blue solid line starts at ~0.2 (0.1B), rises to ~0.7 (10B), and plateaus at ~0.8 (100B).
8. **Entity Decomp.**:
- Orange solid line starts at ~0.45 (0.1B), increases to ~0.8 (10B), and reaches ~0.85 (100B).
### Key Observations
- **Scaling Benefits**: Entity Naming and Entity Decomp. show significant accuracy improvements with larger models, approaching human-level performance (~0.95).
- **Baseline Limitations**: Random and Random Naming models perform poorly, with no improvement despite scaling.
- **Architectural Impact**: CoPINet + ACL achieves ~0.85 accuracy without scaling, outperforming Random but trailing human benchmarks.
- **Convergence**: Entity Decomp. closes the gap to human accuracy most effectively (~0.85 vs. 0.95), while Entity Naming lags slightly (~0.8).
### Interpretation
The data suggests that **model architecture** (e.g., CoPINet + ACL) and **scaling** (e.g., Entity Decomp., Entity Naming) are critical for improving center accuracy. Entity Decomp. demonstrates the strongest synergy between scaling and architectural design, achieving ~90% of human performance at 100B parameters. In contrast, Random models highlight the necessity of structured training, as they fail to improve even at 100B parameters. The flat lines for Human, Rel-AIR, and CoPINet + ACL indicate that these represent fixed benchmarks, with CoPINet + ACL serving as a strong baseline for comparison. The trends underscore the importance of both model capacity and algorithmic innovation in achieving human-like performance.