\n
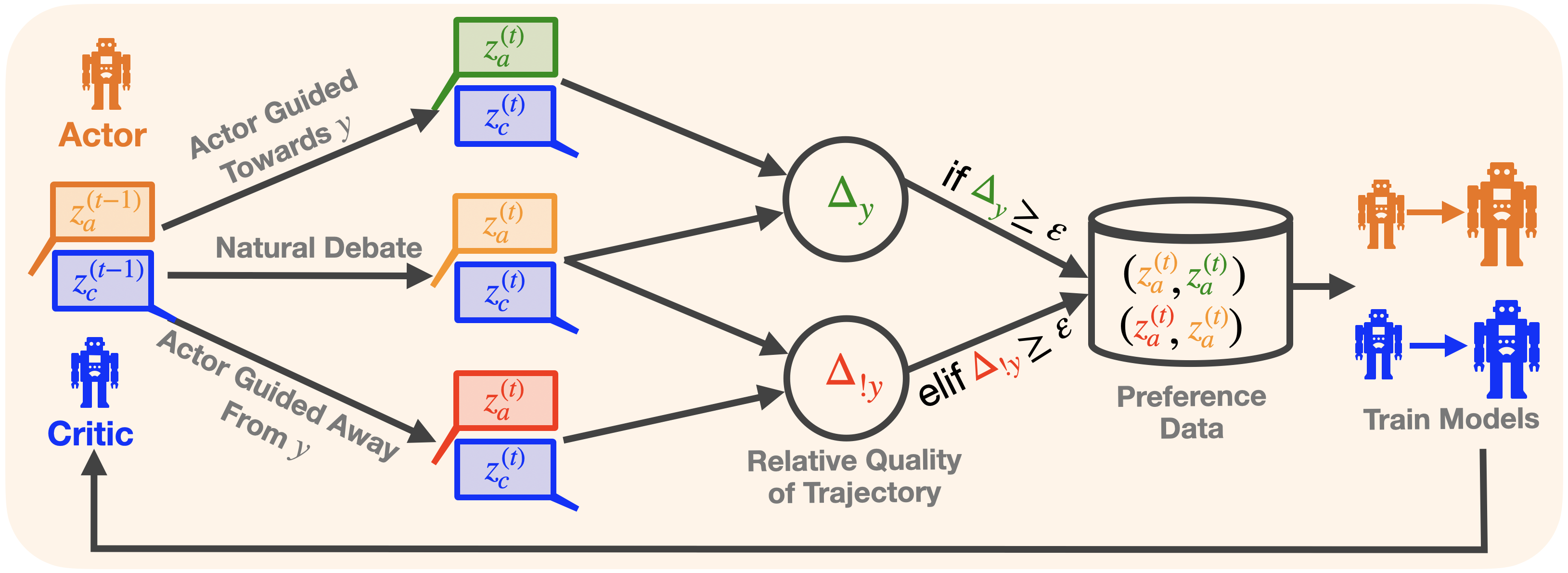
## Diagram: Natural Debate Framework for Training Models
### Overview
This diagram illustrates a "Natural Debate" framework for training models, likely reinforcement learning agents, involving an "Actor" and a "Critic" that interact and generate preference data for further model training. The diagram depicts the flow of information and decision-making processes within this framework.
### Components/Axes
The diagram consists of the following key components:
* **Actor:** Represented by a robot icon, positioned on the left side of the diagram.
* **Critic:** Represented by a robot icon, positioned on the left side of the diagram, below the Actor.
* **Actor Guided Towards y:** A pathway indicating the Actor's actions directed towards a goal 'y'.
* **Actor Guided Away From y:** A pathway indicating the Actor's actions directed away from a goal 'y'.
* **Natural Debate:** A central box encompassing the interaction between the Actor and Critic.
* **z<sub>a</sub><sup>(t)</sup> & z<sub>c</sub><sup>(t)</sup>:** State representations for the Actor and Critic at time 't'. These appear in multiple locations.
* **z<sub>a</sub><sup>(t-1)</sup> & z<sub>c</sub><sup>(t-1)</sup>:** State representations for the Actor and Critic at time 't-1'.
* **Δ<sub>y</sub>:** Represents the difference or change related to 'y'.
* **Δ<sub>ly</sub>:** Represents the local difference or change related to 'y'.
* **Relative Quality of Trajectory:** A label describing the output of the comparison between Δ<sub>y</sub> and a threshold ε.
* **Preference Data:** A box containing the tuple (z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>).
* **Train Models:** A section depicting the use of preference data to train the Actor and Critic models.
### Detailed Analysis or Content Details
The diagram shows a flow of information as follows:
1. **Actor & Critic States:** The Actor and Critic both have state representations denoted as z<sub>a</sub><sup>(t)</sup> and z<sub>c</sub><sup>(t)</sup> at time 't', and z<sub>a</sub><sup>(t-1)</sup> and z<sub>c</sub><sup>(t-1)</sup> at time 't-1'. These states are inputs to the "Natural Debate" process.
2. **Actor Guidance:** The Actor is guided both towards and away from a goal 'y'. This results in two separate pathways.
3. **Natural Debate & Comparison:** Within the "Natural Debate" box, the states are processed to calculate Δ<sub>y</sub> and Δ<sub>ly</sub>.
4. **Decision Logic:** A conditional statement is present:
* **if Δ<sub>y</sub> ≥ ε:** This condition leads to the generation of preference data.
* **elif Δ<sub>ly</sub> ≥ ε:** This condition also leads to the generation of preference data.
5. **Preference Data Generation:** The preference data is represented as a tuple: (z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>, z<sub>a</sub><sup>(t)</sup>). The exact meaning of this tuple is unclear without further context.
6. **Model Training:** The generated preference data is then used to "Train Models" – specifically, the Actor and Critic models. The diagram shows two separate training pathways, one for the Actor and one for the Critic.
### Key Observations
* The diagram emphasizes a comparative learning process where the Actor and Critic evaluate trajectories based on their proximity to a goal 'y'.
* The threshold 'ε' plays a crucial role in determining when preference data is generated.
* The preference data appears to be based on the states of both the Actor and Critic.
* The diagram does not provide specific numerical values or quantitative data. It is a conceptual illustration of a framework.
### Interpretation
The diagram illustrates a novel approach to reinforcement learning training, termed "Natural Debate." The core idea is to have an Actor and a Critic engage in a debate about the quality of trajectories. The Critic evaluates the Actor's actions, and the difference (Δ<sub>y</sub> or Δ<sub>ly</sub>) between the current state and the goal 'y' determines whether preference data is generated. This preference data is then used to refine both the Actor and Critic models.
The use of a threshold 'ε' suggests that only significant deviations from the goal trigger the generation of preference data, potentially focusing the learning process on more challenging or informative scenarios. The "Natural Debate" aspect likely refers to the iterative process of the Actor and Critic challenging each other, leading to more robust and effective learning.
The tuple representing the preference data is somewhat ambiguous. It could represent a comparison of states, or a ranking of trajectories. Without further context, it's difficult to determine its precise meaning.
The diagram is a high-level overview and does not delve into the specific algorithms or implementation details of the "Natural Debate" framework. It serves as a conceptual blueprint for a potentially powerful learning paradigm.