TECHNICAL ASSET FINGERPRINT
6786f68e4a81e4c25fc6dcab
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
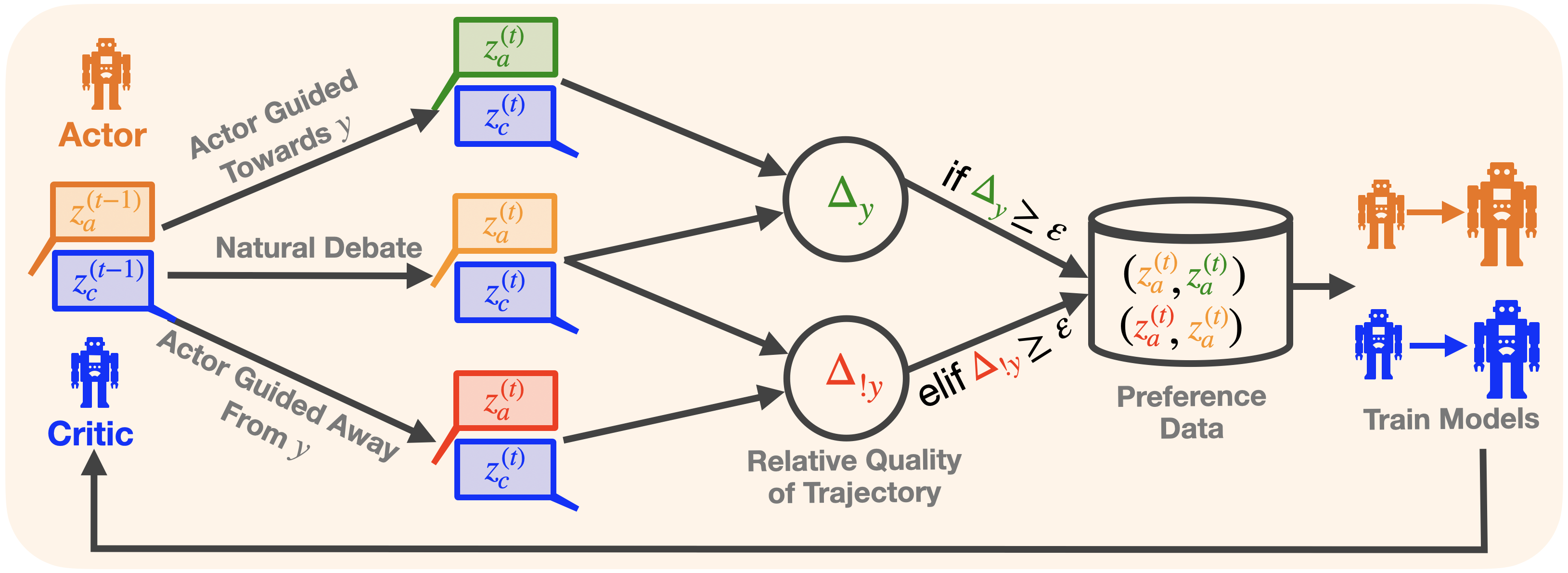
## Diagram: Actor-Critic Preference-Based Training Process
### Overview
The image is a technical flowchart illustrating a machine learning training process involving two agents: an "Actor" and a "Critic." The process generates preference data by comparing the quality of different trajectories (sequences of states/actions) produced under three distinct guidance conditions. This data is then used to train models, with the Critic receiving feedback from the training outcomes.
### Components/Axes
The diagram is structured as a left-to-right flowchart with a feedback loop. Key components are labeled with text and mathematical notation.
**Left Side (Agents & Initial State):**
* **Actor:** Represented by an orange robot icon and the label "Actor" in orange text. Positioned at the top-left.
* **Critic:** Represented by a blue robot icon and the label "Critic" in blue text. Positioned at the bottom-left.
* **Initial State:** Two stacked speech bubbles represent the state at time `t-1`.
* Top bubble (orange outline): Contains the text `z_a^{(t-1)}`.
* Bottom bubble (blue outline): Contains the text `z_c^{(t-1)}`.
**Central Process (Three Parallel Paths):**
Three arrows originate from the initial state bubbles, each labeled with a process name and leading to a pair of output bubbles at time `t`.
1. **Top Path:** Labeled "Actor Guided Towards y". Leads to:
* A green-outlined bubble containing `z_a^{(t)}`.
* A blue-outlined bubble containing `z_c^{(t)}`.
2. **Middle Path:** Labeled "Natural Debate". Leads to:
* An orange-outlined bubble containing `z_a^{(t)}`.
* A blue-outlined bubble containing `z_c^{(t)}`.
3. **Bottom Path:** Labeled "Actor Guided Away From y". Leads to:
* A red-outlined bubble containing `z_a^{(t)}`.
* A blue-outlined bubble containing `z_c^{(t)}`.
**Comparison & Decision Nodes:**
The outputs from the three paths feed into two circular comparison nodes.
* **Top Node:** Contains the symbol `Δ_y` (Delta subscript y). It receives inputs from the top path's green `z_a^{(t)}` and the middle path's orange `z_a^{(t)}`.
* **Bottom Node:** Contains the symbol `Δ_{!y}` (Delta subscript exclamation-mark y). It receives inputs from the middle path's orange `z_a^{(t)}` and the bottom path's red `z_a^{(t)}`.
* **Label:** Below these nodes is the text "Relative Quality of Trajectory".
**Data Storage & Training:**
* **Decision Logic:** Arrows from the comparison nodes lead to a database icon. The arrows are labeled with conditional statements:
* From `Δ_y`: "if `Δ_y ≥ ε`" (if Delta y is greater than or equal to epsilon).
* From `Δ_{!y}`: "elif `Δ_{!y} ≥ ε`" (else if Delta not-y is greater than or equal to epsilon).
* **Database:** A cylinder icon labeled "Preference Data". Inside, it contains two pairs of notations:
* `(z_a^{(t)}, z_a^{(t)})` (The first `z_a` is in orange, the second in green).
* `(z_a^{(t)}, z_a^{(t)})` (The first `z_a` is in orange, the second in red).
* **Training Output:** An arrow points from the database to the right, where two robot icons (orange and blue) are shown transforming into larger versions. This section is labeled "Train Models".
**Feedback Loop:**
A thick black arrow originates from the "Train Models" section, travels along the bottom of the diagram, and points back to the "Critic" icon on the left, indicating a feedback mechanism.
### Detailed Analysis
The diagram details a method for generating comparative preference data for training AI models.
1. **Trajectory Generation:** Starting from a shared previous state (`z_a^{(t-1)}`, `z_c^{(t-1)}`), three different trajectories are generated for the next time step (`t`):
* One where the Actor is guided toward a target `y`.
* One resulting from a "Natural Debate" (presumably unguided or standard interaction).
* One where the Actor is guided away from target `y`.
The Critic's state (`z_c^{(t)}`) is generated alongside the Actor's (`z_a^{(t)}`) in each case.
2. **Quality Comparison:** The system compares the Actor's states from different trajectories:
* `Δ_y` compares the "guided towards y" Actor state (green) with the "natural debate" Actor state (orange).
* `Δ_{!y}` compares the "natural debate" Actor state (orange) with the "guided away from y" Actor state (red).
The label "Relative Quality of Trajectory" indicates these deltas measure a quality difference.
3. **Preference Data Creation:** If the quality difference (`Δ`) exceeds a threshold `ε` (epsilon), the pair of compared Actor states is stored as a preference datum in the database. The notation in the database shows the "natural debate" state (orange) is paired with either the "guided towards" state (green) or the "guided away" state (red), implying a preference ordering.
4. **Model Training & Feedback:** The collected preference data is used to "Train Models." The updated models (represented by larger robot icons) then provide feedback to the Critic, closing the loop and presumably improving its future evaluations.
### Key Observations
* **Color Coding is Critical:** The outline color of the `z_a^{(t)}` bubbles (green, orange, red) is essential for tracking which trajectory they came from and how they are paired in the database.
* **Conditional Logic:** Data is only stored if the relative quality difference is significant (≥ ε), filtering out trivial comparisons.
* **Asymmetric Roles:** The Actor generates the primary trajectories (`z_a`), while the Critic's state (`z_c`) is generated in parallel but is not directly compared. The Critic's main role appears to be in the feedback loop after training.
* **Feedback Loop:** The system is iterative; training outputs influence the Critic, which will affect future trajectory evaluations.
### Interpretation
This diagram depicts a sophisticated **preference-based reinforcement learning or alignment training scheme**. The core idea is to create a dataset of *comparative preferences* rather than absolute rewards.
* **What it demonstrates:** The process systematically generates "good" (guided toward y) and "bad" (guided away from y) examples relative to a baseline (natural debate). By comparing these, it learns what makes a trajectory preferable with respect to the target `y`. The threshold `ε` ensures only clear preferences are learned.
* **How elements relate:** The Actor is the policy being trained. The Critic is likely a value function or reward model that is being improved via the feedback loop. The "Natural Debate" path serves as a crucial control or reference point. The database of preference pairs `(winner, loser)` is the key training signal.
* **Notable implications:** This method could be used for **Constitutional AI** or **RLHF (Reinforcement Learning from Human Feedback)**, where `y` represents a desired behavior (e.g., helpfulness, harmlessness). The "Actor Guided Away From y" path is particularly interesting, as it actively generates negative examples to contrast against. The feedback to the Critic suggests an **adversarial or co-evolutionary dynamic** where the evaluator (Critic) improves alongside the generator (Actor).
DECODING INTELLIGENCE...