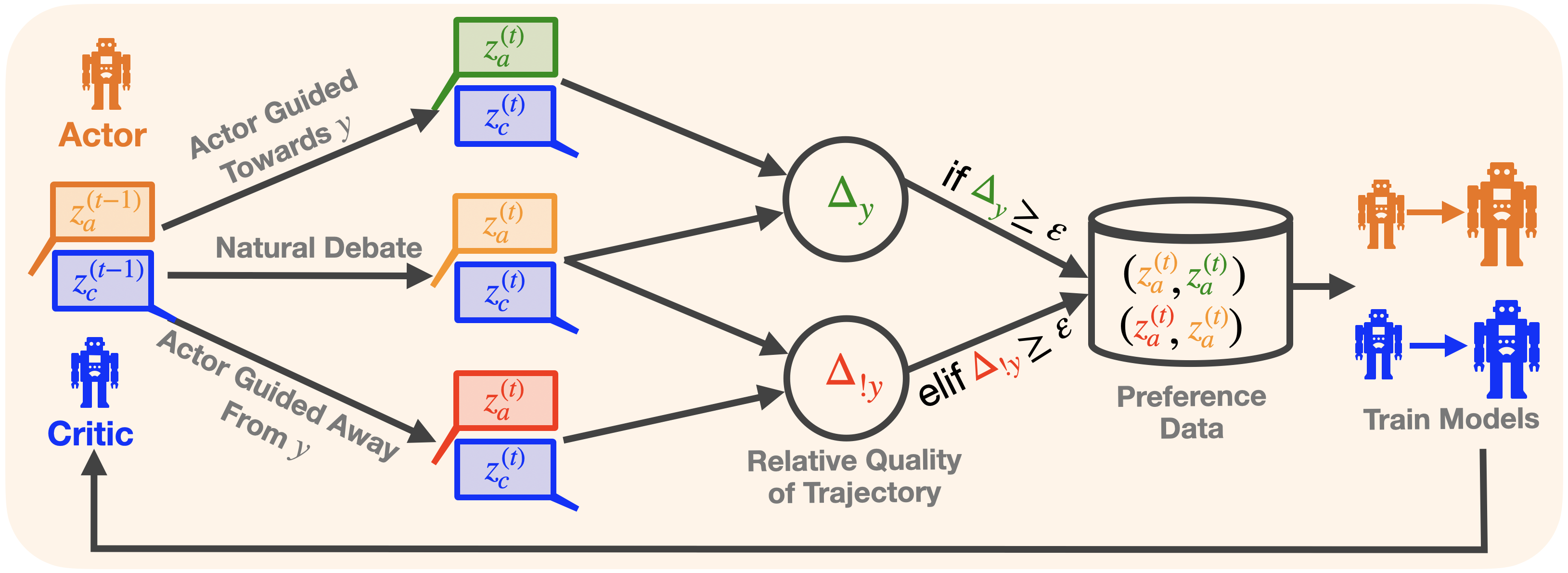
## Diagram: Actor-Critic Framework with Preference-Based Training
### Overview
This diagram illustrates a technical framework involving an **Actor** and a **Critic** in a decision-making or optimization process. The system uses **Natural Debate**, **Actor-Guided Trajectories**, and **Preference Data** to train models. Mathematical notations (e.g., Δy, Δ!y) and symbolic representations (e.g., z_a^(t), z_c^(t)) indicate dynamic interactions between components.
---
### Components/Axes
1. **Key Elements**:
- **Actor**: Represented by an orange robot icon. Processes include:
- `z_a^(t-1)` (previous Actor state)
- `z_a^(t)` (current Actor state)
- **Critic**: Represented by a blue robot icon. Processes include:
- `z_c^(t-1)` (previous Critic state)
- `z_c^(t)` (current Critic state)
- **Natural Debate**: A bidirectional process between Actor and Critic.
- **Actor Guided Toward y**: A green arrow indicating trajectory adjustment.
- **Actor Guided Away From y**: A red arrow indicating trajectory adjustment.
- **Relative Quality of Trajectory**: A circular node with Δy (green) and Δ!y (red) symbols.
- **Preference Data**: A database storing pairs of trajectories (z_a^(t), z_a^(t)) and (z_a^(t), z_a^(t)).
- **Train Models**: A final step where models are trained using preference data.
2. **Flow Direction**:
- Arrows indicate the sequence of operations:
- Actor and Critic states evolve over time (t-1 → t).
- Natural Debate influences trajectory adjustments.
- Preference data is generated based on relative quality metrics (Δy, Δ!y).
- Models are trained using this data.
3. **Mathematical Notations**:
- Δy: Likely represents a quality metric for trajectories.
- Δ!y: Likely represents an alternative or negative quality metric.
- ε: A threshold value for preference data inclusion.
---
### Detailed Analysis
1. **Actor-Critic Interaction**:
- The Actor proposes trajectories (z_a^(t)), while the Critic evaluates them (z_c^(t)).
- The Critic's feedback guides the Actor to adjust trajectories toward or away from a target (y).
2. **Natural Debate**:
- A dynamic exchange between Actor and Critic states (z_a^(t-1) ↔ z_c^(t-1)) to refine decisions.
3. **Trajectory Adjustment**:
- **Toward y**: Green arrow (Δy ≥ ε) indicates acceptable trajectories.
- **Away From y**: Red arrow (Δ!y ≥ ε) indicates suboptimal trajectories.
4. **Preference Data**:
- Stores pairs of trajectories (z_a^(t), z_a^(t)) and (z_a^(t), z_a^(t)) for training.
- Only trajectories meeting the threshold (Δy ≥ ε or Δ!y ≥ ε) are included.
5. **Model Training**:
- Final step uses preference data to optimize the Actor and Critic models.
---
### Key Observations
- **Threshold-Driven Process**: The system relies on ε to filter trajectories for preference data.
- **Bidirectional Feedback**: The Critic's evaluation directly influences the Actor's trajectory adjustments.
- **Symbolic Representation**: Mathematical notations (Δy, Δ!y) abstract the quality evaluation process.
---
### Interpretation
This diagram represents a **reinforcement learning** or **preference-based optimization** system. The Actor-Critic framework is a common approach in machine learning, where the Actor generates actions (trajectories) and the Critic evaluates their quality. The "Natural Debate" suggests a collaborative refinement process, while the "Relative Quality of Trajectory" introduces a comparative metric (Δy vs. Δ!y) to prioritize data. The final step of training models on preference data implies a focus on aligning the system with human or predefined preferences, likely for tasks requiring subjective judgment (e.g., recommendation systems, autonomous decision-making). The use of ε as a threshold ensures only high-quality trajectories contribute to training, reducing noise in the learning process.