## Diagram: Knowledge Retrieval Process
### Overview
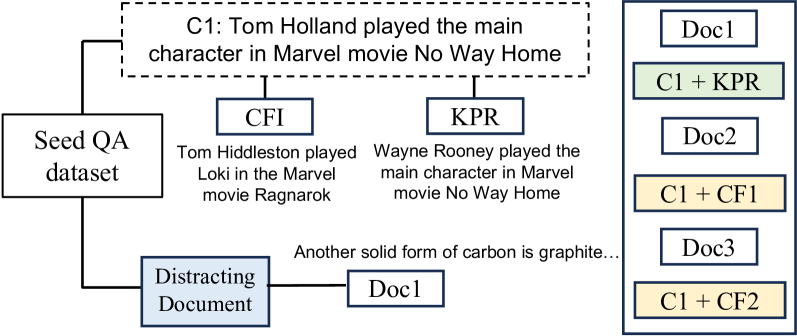
The image is a diagram illustrating a knowledge retrieval process. It shows how a "Seed QA dataset" is used to retrieve relevant documents, incorporating different types of information such as common facts, knowledge principles, and distracting information.
### Components/Axes
* **Seed QA dataset**: A rectangular box labeled "Seed QA dataset" on the left side of the diagram.
* **C1**: A dashed rectangular box at the top, containing the text "C1: Tom Holland played the main character in Marvel movie No Way Home".
* **CFI**: A blue rectangular box below C1, containing the text "Tom Hiddleston played Loki in the Marvel movie Ragnarok".
* **KPR**: A blue rectangular box to the right of CFI, containing the text "Wayne Rooney played the main character in Marvel movie No Way Home".
* **Distracting Document**: A blue rectangular box at the bottom, containing the text "Distracting Document". Below it is the text "Another solid form of carbon is graphite...".
* **Document List**: A blue outlined box on the right side containing a list of documents:
* Doc1
* C1 + KPR (Green background)
* Doc2
* C1 + CF1 (Yellow background)
* Doc3
* C1 + CF2 (Yellow background)
### Detailed Analysis
* The "Seed QA dataset" is connected to both "C1" and "Distracting Document" via solid black lines.
* "C1" is connected to "CFI" and "KPR" via solid black lines.
* "Distracting Document" is connected to "Doc1" via a solid black line.
* The document list on the right shows different documents and their content. "Doc1", "Doc2", and "Doc3" have white backgrounds. "C1 + KPR" has a green background. "C1 + CF1" and "C1 + CF2" have yellow backgrounds.
### Key Observations
* The diagram illustrates how different types of information (C1, CFI, KPR, Distracting Document) are used to retrieve and categorize documents.
* The use of color-coding (green and yellow backgrounds) in the document list suggests different categories or levels of relevance.
### Interpretation
The diagram represents a knowledge retrieval system that uses a seed dataset to find relevant documents. It incorporates common facts (C1), knowledge principles (KPR), and common facts inferred (CFI). The "Distracting Document" component suggests the system also considers irrelevant or misleading information. The document list on the right shows the results of the retrieval process, with documents categorized based on the information they contain. The color-coding likely indicates the relevance or confidence level of each document. The system seems to be designed to identify documents containing specific combinations of facts and principles, while also accounting for potential distractions.