\n
## Diagram: Question Answering Dataset Generation Flow
### Overview
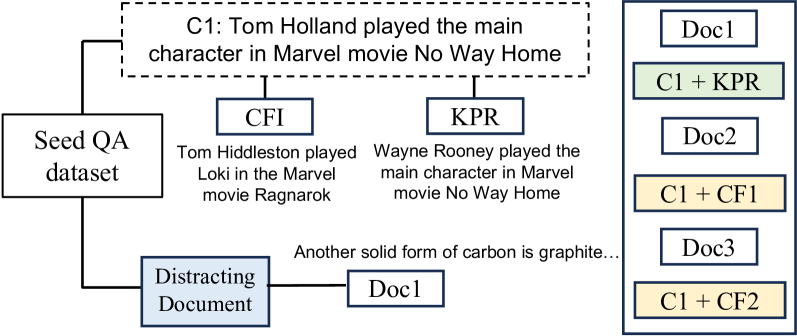
This diagram illustrates the process of generating a Question Answering (QA) dataset. It shows how a "Seed QA dataset" is used to create variations and ultimately generate new documents (Doc1, Doc2, Doc3) with associated question-answer pairs. The diagram highlights the creation of "Contextualized Fact Identification" (CFI) and "Key Phrase Retrieval" (KPR) components, and their combination with the original seed data.
### Components/Axes
The diagram consists of several rectangular blocks representing different components and documents, connected by arrows indicating the flow of information. Key components include:
* **Seed QA dataset:** The initial dataset used as a starting point.
* **C1:** A statement: "Tom Holland played the main character in Marvel movie No Way Home". This is enclosed in a dashed box.
* **CFI:** "Tom Hiddleston played Loki in the Marvel movie Ragnarok".
* **KPR:** "Wayne Rooney played the main character in Marvel movie No Way Home".
* **Distracting Document:** A document containing irrelevant information: "Another solid form of carbon is graphite...".
* **Doc1:** A document.
* **Doc2:** A document.
* **Doc3:** A document.
* **C1 + KPR:** A combined document.
* **C1 + CFI:** A combined document.
* **C1 + CF2:** A combined document.
Arrows indicate the direction of data flow and generation.
### Detailed Analysis / Content Details
The diagram shows the following flow:
1. The "Seed QA dataset" branches into three paths:
* One path leads to the creation of "CFI" and "KPR" components, both originating from the statement "C1: Tom Holland played the main character in Marvel movie No Way Home".
* Another path leads to a "Distracting Document".
* The third path leads directly to "Doc1".
2. "CFI" and "KPR" are then combined with "C1" to create "C1 + KPR".
3. "CFI" is combined with "Doc1" to create "Doc2".
4. "CF2" (not explicitly defined, but implied) is combined with "Doc1" to create "Doc3".
The text within each block is as follows:
* **C1:** "Tom Holland played the main character in Marvel movie No Way Home"
* **CFI:** "Tom Hiddleston played Loki in the Marvel movie Ragnarok"
* **KPR:** "Wayne Rooney played the main character in Marvel movie No Way Home"
* **Distracting Document:** "Another solid form of carbon is graphite..."
* **Doc1:** "Doc1"
* **Doc2:** "Doc2"
* **Doc3:** "Doc3"
* **C1 + KPR:** "C1 + KPR"
* **C1 + CFI:** "C1 + CFI"
* **C1 + CF2:** "C1 + CF2"
### Key Observations
The diagram demonstrates a method for augmenting a QA dataset by creating variations of existing facts. The "CFI" and "KPR" components appear to represent different ways of retrieving or identifying relevant information. The "Distracting Document" suggests a strategy for introducing negative examples to improve the robustness of the QA model. The combination of "C1" with "KPR" and "CFI" indicates a process of enriching the original fact with related information.
### Interpretation
This diagram illustrates a data augmentation technique for building a QA dataset. The core idea is to start with a seed dataset and generate new examples by:
* **Fact Variation:** Creating "CFI" and "KPR" which represent different ways to express or retrieve the same underlying fact. "KPR" seems to be a deliberately incorrect statement, introducing a challenge for the QA system.
* **Contextualization:** Combining the original fact ("C1") with these variations to create more complex examples.
* **Distraction:** Introducing irrelevant information ("Distracting Document") to force the QA model to focus on the relevant parts of the context.
The resulting documents (Doc1, Doc2, Doc3) represent a more diverse and challenging QA dataset than the original seed dataset. The process aims to improve the QA model's ability to identify correct answers even in the presence of noise and variations in phrasing. The diagram suggests a systematic approach to dataset generation, focusing on creating both positive and negative examples to enhance the model's performance.