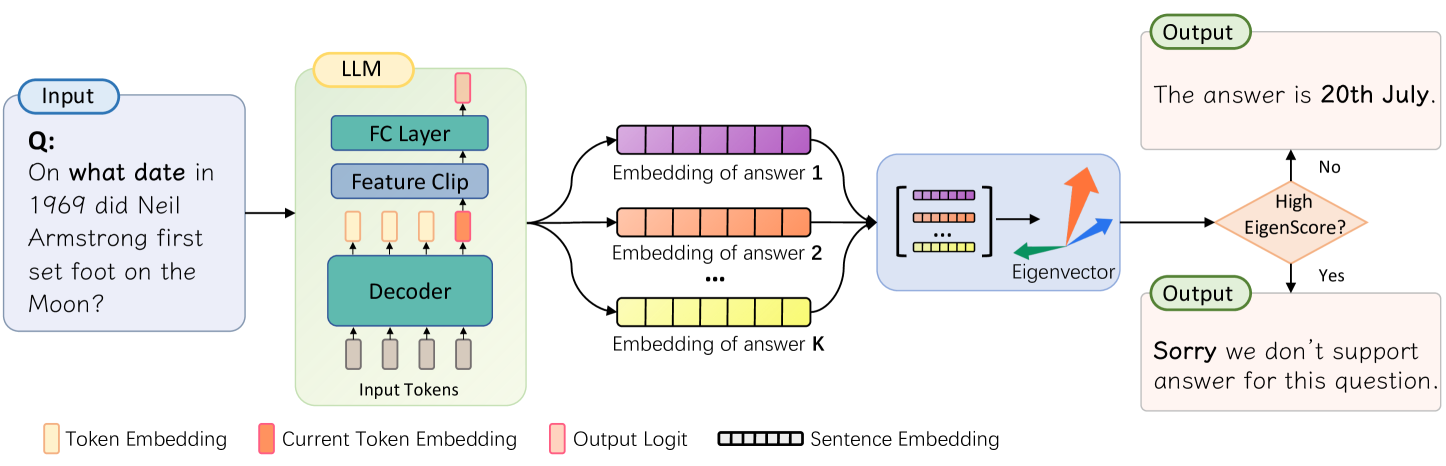
## Diagram: LLM Question Answering Process
### Overview
The image is a diagram illustrating the process of a Language Model (LLM) answering a question. It shows the flow of information from the input question, through the LLM's internal components, to the final output. The diagram includes decision-making based on an "EigenScore" to determine if the LLM can provide a supported answer.
### Components/Axes
* **Input:** A rounded rectangle labeled "Input" containing the question: "Q: On what date in 1969 did Neil Armstrong first set foot on the Moon?".
* **LLM:** A rounded rectangle labeled "LLM" containing the following components:
* FC Layer (Fully Connected Layer)
* Feature Clip
* Decoder
* Input Tokens (represented by gray rectangles)
* **Embedding of answer 1:** A series of connected purple rectangles.
* **Embedding of answer 2:** A series of connected orange rectangles.
* **Embedding of answer K:** A series of connected yellow rectangles.
* **Eigenvector:** A blue rounded rectangle containing a matrix of embeddings and three vectors (orange, blue, and green) labeled "Eigenvector".
* **High EigenScore?:** A diamond shape colored orange, used as a decision point.
* **Output (Top):** A rounded rectangle labeled "Output" containing the answer: "The answer is 20th July.".
* **Output (Bottom):** A rounded rectangle labeled "Output" containing the statement: "Sorry we don't support answer for this question.".
* **Legend (Bottom):**
* Token Embedding (light yellow rectangle)
* Current Token Embedding (light orange rectangle)
* Output Logit (light pink rectangle)
* Sentence Embedding (black outlined rectangle)
### Detailed Analysis or ### Content Details
1. **Input:** The input question is "On what date in 1969 did Neil Armstrong first set foot on the Moon?".
2. **LLM Processing:**
* The input tokens are fed into the Decoder.
* The Decoder's output is processed by the Feature Clip and FC Layer.
3. **Answer Embeddings:** The LLM generates multiple answer embeddings (1, 2, ..., K), represented by sequences of colored rectangles (purple, orange, yellow).
4. **Eigenvector Calculation:** The answer embeddings are combined and processed to calculate an Eigenvector.
5. **Decision Point:** The EigenScore is evaluated.
* If the EigenScore is high ("Yes"), the LLM outputs "Sorry we don't support answer for this question.".
* If the EigenScore is not high ("No"), the LLM outputs "The answer is 20th July.".
### Key Observations
* The diagram illustrates a question-answering system using an LLM.
* The LLM processes the input question and generates multiple potential answers.
* An Eigenvector is calculated based on the answer embeddings.
* The EigenScore is used to determine if the LLM can provide a supported answer.
* If the EigenScore is not high, the LLM provides an answer. If it is high, the LLM indicates that it cannot support the question.
### Interpretation
The diagram depicts a system where an LLM attempts to answer a question. The use of an EigenScore suggests a confidence or relevance metric. If the LLM is confident in its answer (low EigenScore), it provides the answer. If the LLM is not confident (high EigenScore), it declines to answer, indicating a mechanism for avoiding incorrect or unsupported responses. The "Sorry we don't support answer for this question" output suggests a fallback mechanism when the LLM's confidence in its answer is low. The diagram highlights the complexity of question-answering systems, including the need for confidence metrics and fallback mechanisms.