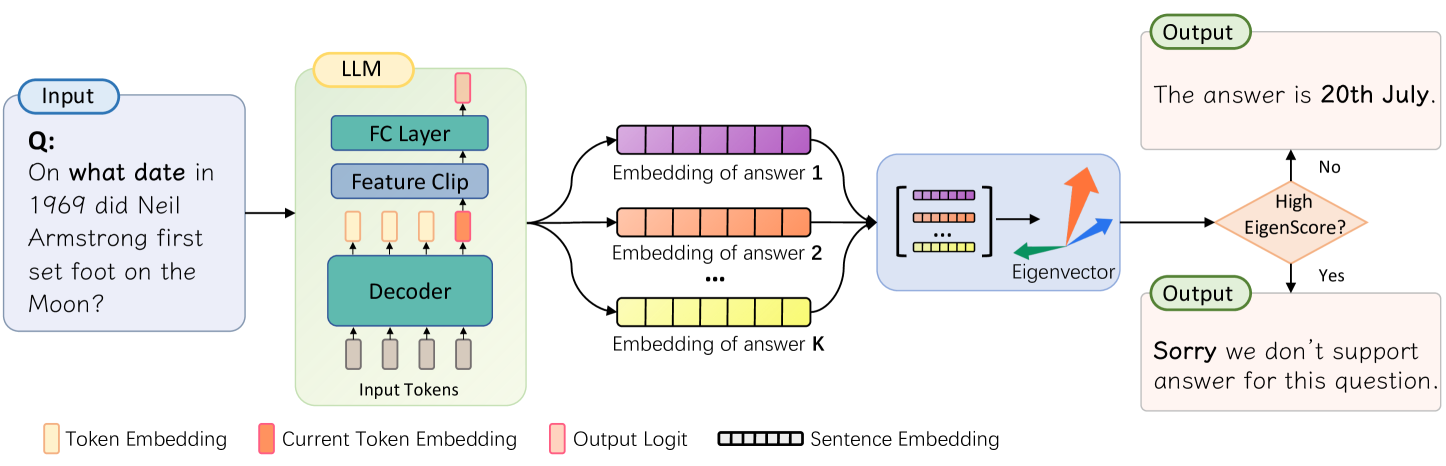
## Diagram Type: LLM Uncertainty/Verification Workflow using EigenScore
### Overview
This technical diagram illustrates a process for evaluating the reliability of a Large Language Model (LLM) response. It depicts a pipeline where an input question is processed by an LLM to generate multiple candidate answer embeddings. These embeddings are then analyzed using eigenvector decomposition to calculate an "EigenScore." Based on this score, the system decides whether to provide a direct answer or a refusal message, likely to mitigate hallucinations or low-confidence outputs.
### Components/Axes
#### 1. Legend (Bottom)
Located at the bottom of the image, the legend defines the visual symbols used throughout the diagram:
* **Token Embedding:** Represented by a light orange vertical rectangle.
* **Current Token Embedding:** Represented by a solid orange vertical rectangle.
* **Output Logit:** Represented by a pink vertical rectangle with a red border.
* **Sentence Embedding:** Represented by a horizontal bar divided into segments (colored purple, orange, or yellow).
#### 2. Input Section (Far Left)
* **Label:** "Input" (blue pill-shaped header).
* **Content:** A light blue box containing the text: "Q: On what date in 1969 did Neil Armstrong first set foot on the Moon?"
#### 3. LLM Architecture (Center-Left)
* **Label:** "LLM" (yellow pill-shaped header).
* **Container:** A light green rounded rectangle.
* **Internal Flow (Bottom to Top):**
* **Input Tokens:** A sequence of four vertical rectangles (three light orange "Token Embeddings" followed by one solid orange "Current Token Embedding").
* **Decoder:** A teal horizontal block receiving the input tokens.
* **Intermediate State:** Another sequence of four rectangles (three light orange, one solid orange) above the Decoder.
* **Feature Clip:** A blue horizontal block.
* **FC Layer (Fully Connected):** A teal horizontal block.
* **Output Logit:** A single pink rectangle at the top of the stack.
#### 4. Embedding Generation (Center)
* Three distinct horizontal segmented bars representing different answer candidates:
* **Top (Purple):** "Embedding of answer 1"
* **Middle (Orange):** "Embedding of answer 2"
* **Bottom (Yellow):** "Embedding of answer K" (where 'K' implies multiple samples).
* An ellipsis ("...") is placed between the second and K-th embedding to indicate a variable number of samples.
#### 5. Analysis Block (Center-Right)
* **Container:** A light blue rounded rectangle.
* **Content:**
* A matrix representation stacking the purple, orange, and yellow sentence embeddings.
* An arrow pointing to a 3D coordinate system with three colored arrows (green, blue, and orange) labeled "**Eigenvector**".
#### 6. Decision Logic and Output (Far Right)
* **Decision Node:** An orange diamond labeled "**High EigenScore?**".
* **Path "No" (Upward):** Leads to an "Output" box (light orange) containing: "The answer is **20th July**."
* **Path "Yes" (Downward):** Leads to an "Output" box (light orange) containing: "**Sorry** we don't support answer for this question."
---
### Content Details
#### Process Flow
1. **Input:** The system receives a factual query about Neil Armstrong.
2. **Processing:** The LLM processes the input tokens through its internal layers (Decoder, Feature Clip, FC Layer).
3. **Sampling:** Instead of a single output, the system generates $K$ different sentence embeddings for potential answers.
4. **Mathematical Analysis:** These $K$ embeddings are aggregated into a matrix. Eigenvector analysis is performed on this matrix to determine the variance or consistency between the answers.
5. **Scoring:** An "EigenScore" is derived from this analysis.
6. **Branching:**
* If the EigenScore is **not high** (indicating high consensus/low variance among samples), the system outputs the factual answer.
* If the EigenScore is **high** (indicating high variance/uncertainty among samples), the system triggers a safety refusal.
---
### Key Observations
* **Multi-Sample Verification:** The diagram emphasizes that the system doesn't rely on a single pass but generates multiple "embeddings of answer 1...K" to check for consistency.
* **Feature Clipping:** The inclusion of a "Feature Clip" layer within the LLM block suggests a specific architectural modification to regularize or bound the features before the final classification/logit layer.
* **Inverse Logic:** Usually, a "high" score is good, but here a "High EigenScore" leads to a refusal. This suggests the EigenScore measures dispersion or entropy—the higher the score, the more "spread out" and inconsistent the candidate answers are.
---
### Interpretation
This diagram represents a **Self-Check or Uncertainty Estimation mechanism** for LLMs.
The use of "Eigenvectors" suggests that the system is performing a Principal Component Analysis (PCA) or a similar spectral analysis on the latent space of multiple generated answers.
* If the generated answers are semantically similar, their embeddings will cluster together, resulting in a dominant primary eigenvector and a **low EigenScore** (low dispersion). This gives the system "confidence" to provide the answer "20th July."
* If the generated answers are wildly different (hallucinations or conflicting facts), the embeddings will be scattered. This results in a **high EigenScore**, signaling that the model is "confused" or "uncertain," prompting the system to provide a canned refusal message to avoid spreading misinformation.
This is a sophisticated approach to the "hallucination" problem in AI, moving beyond simple probability scores to a more robust geometric analysis of the model's internal representations across multiple samples.