\n
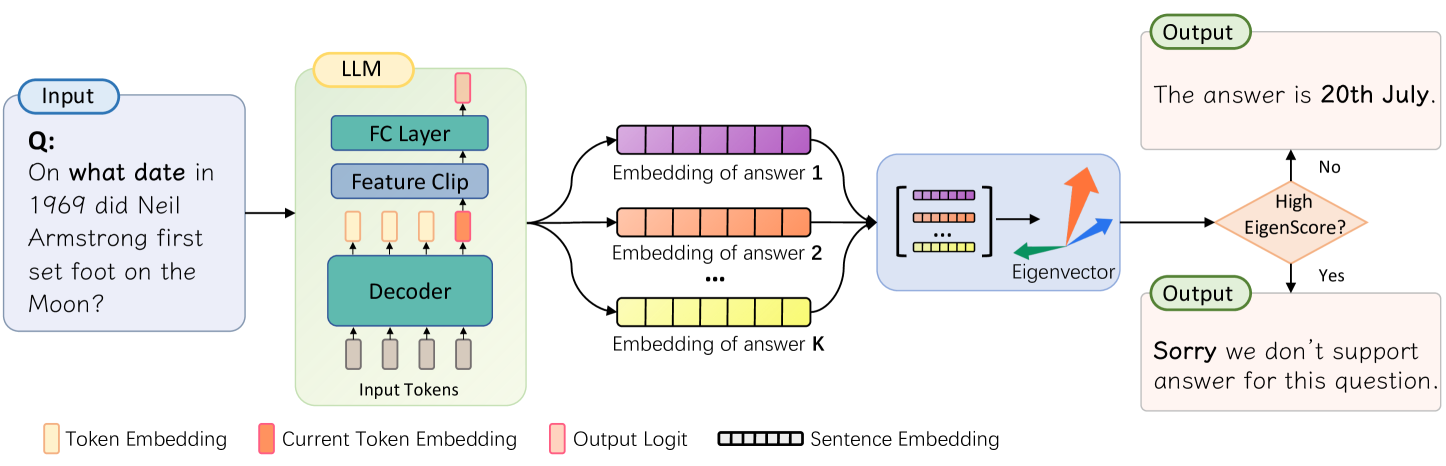
## Diagram: LLM Answer Selection Process
### Overview
This diagram illustrates the process by which a Large Language Model (LLM) selects an answer to a given question. The process involves generating multiple answer embeddings, evaluating them using an eigenvector, and outputting the best answer or a rejection message if the score is too low.
### Components/Axes
The diagram consists of the following components:
* **Input:** A question posed to the LLM. The question is: "On what date in 1969 did Neil Armstrong first set foot on the Moon?".
* **LLM:** The core of the system, composed of:
* **Decoder:** Processes input tokens.
* **Feature Clip:** Transforms the decoder output.
* **FC Layer:** Further processes the features.
* **Answer Embeddings:** Multiple embeddings generated from the LLM, labeled "Embedding of answer 1", "Embedding of answer 2", and "Embedding of answer K".
* **Eigenvector:** A vector used to evaluate the quality of the answer embeddings.
* **Output:** The final answer or a rejection message. Two possible outputs are shown: "The answer is 20th July." and "Sorry we don't support answer for this question."
* **Legend:** Provides color-coding for different data types:
* Yellow: Token Embedding
* Light Green: Current Token Embedding
* Red: Output Logit
* Black & White Striped: Sentence Embedding
### Detailed Analysis or Content Details
The diagram shows a flow of information from the input question through the LLM to the output answer.
1. **Input Processing:** The question is fed into the LLM.
2. **LLM Processing:** The LLM's decoder processes the input tokens. The output of the decoder is passed through a Feature Clip and then an FC Layer.
3. **Answer Generation:** The LLM generates 'K' number of answer embeddings. Each embedding is represented as a series of colored blocks (black and white striped).
4. **Eigenvector Evaluation:** The answer embeddings are compared to an eigenvector. A curved arrow indicates the direction of comparison.
5. **Decision Point:** A decision is made based on whether the "EigenScore" is high enough.
* **High EigenScore (Yes):** The LLM outputs the answer: "The answer is 20th July."
* **Low EigenScore (No):** The LLM outputs a rejection message: "Sorry we don't support answer for this question."
### Key Observations
* The LLM generates multiple potential answers (up to K) before selecting the best one.
* The eigenvector serves as a quality filter, ensuring that only high-confidence answers are outputted.
* The system has a mechanism for handling questions it cannot answer.
* The diagram does not provide specific numerical values for the EigenScore threshold.
### Interpretation
This diagram illustrates a sophisticated answer selection process within an LLM. The use of multiple answer embeddings and an eigenvector suggests a probabilistic approach to answer generation and evaluation. The eigenvector likely represents a desired characteristic of a good answer (e.g., relevance, coherence, factual accuracy). The system is designed to avoid providing incorrect or unsupported answers by rejecting low-confidence responses. The diagram highlights the importance of not only generating potential answers but also rigorously evaluating their quality before presenting them to the user. The 'K' number of embeddings suggests a search for the best answer within a set of possibilities, rather than a deterministic output. The diagram is a conceptual illustration and does not provide details on the specific algorithms or parameters used in the LLM.