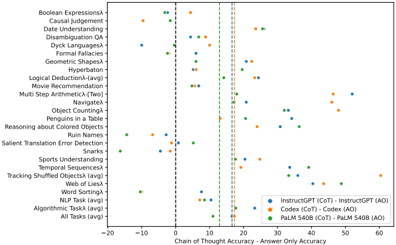
## Scatter Plot: Chain of Thought vs. Answer Only Accuracy Across Tasks
### Overview
The image is a scatter plot comparing the performance of three AI models (InstructGPT, Codex, PaLM 540B) on 20+ reasoning tasks. The x-axis measures the difference between Chain of Thought (CoT) and Answer Only (AO) accuracies, while the y-axis lists specific tasks. Three colored data series represent the models, with vertical lines marking accuracy thresholds.
### Components/Axes
- **X-axis**: "Chain of Thought Accuracy - Answer Only Accuracy" (range: -20 to 60, increments of 10)
- **Y-axis**: Tasks (e.g., Boolean Expressions, Causal Judgement, Sports Understanding)
- **Legend**:
- Blue: InstructGPT (CoT) - InstructGPT (AO)
- Orange: Codex (CoT) - Codex (AO)
- Green: PaLM 540B (CoT) - PaLM 540B (AO)
- **Vertical Lines**: Dashed lines at x=0, 10, 20, 30, 40, 50, 60
### Detailed Analysis
1. **Task Distribution**:
- Tasks cluster across the y-axis, with "All Tasks (avg)" at the bottom.
- High-performing tasks (e.g., "Geometric Shapes") show PaLM 540B (green) dots near x=30-40.
- Low-performing tasks (e.g., "Ruin Names") have InstructGPT (blue) near x=5-10.
2. **Model Performance**:
- **PaLM 540B (green)**: Consistently rightmost dots (x=15-45), indicating higher CoT-AO accuracy.
- **Codex (orange)**: Middle-range performance (x=5-25), with outliers like "Penguins in a Table" at x=10.
- **InstructGPT (blue)**: Leftmost dots (x=-5 to 15), often overlapping with Codex.
3. **Thresholds**:
- Vertical lines at x=0 (baseline), 10, 20, etc., suggest performance benchmarks.
- Most PaLM 540B dots exceed x=10, while InstructGPT rarely crosses x=10.
### Key Observations
- **PaLM 540B Dominance**: Outperforms others in most tasks, especially "All Tasks (avg)" (x≈40).
- **Codex Variability**: Mixed results, with some tasks (e.g., "Tracking Shuffled Objects") near x=20.
- **InstructGPT Limitations**: Struggles with complex reasoning (e.g., "Dyck Languages" at x≈5).
- **Negative Values**: Rare (e.g., "Ruin Names" for InstructGPT at x≈-5), indicating AO > CoT.
### Interpretation
The data demonstrates that **PaLM 540B** excels in CoT reasoning across diverse tasks, likely due to its scale and training. **Codex** shows moderate performance, while **InstructGPT** lags, particularly in multi-step or abstract tasks. The vertical lines may represent industry benchmarks, with PaLM 540B surpassing them in most cases. Outliers like "Penguins in a Table" (Codex at x=10) suggest task-specific strengths. The negative values for InstructGPT highlight potential overfitting to AO patterns. This aligns with prior research on model scaling and reasoning capabilities.