TECHNICAL ASSET FINGERPRINT
683decf23be0108b5708a776
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
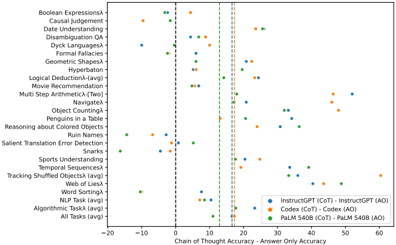
## Scatter Plot: Chain of Thought Accuracy vs. Answer Only Accuracy for Various Tasks
### Overview
The image is a scatter plot comparing the accuracy of "Chain of Thought" (CoT) and "Answer Only" (AO) approaches for different language models (InstructGPT, Codex, and PaLM 540B) across a range of tasks. The x-axis represents the accuracy difference (CoT - AO), and the y-axis lists the tasks. Each data point represents the accuracy difference for a specific model and task.
### Components/Axes
* **X-axis:** "Chain of Thought Accuracy - Answer Only Accuracy". The scale ranges from -20 to 60, with tick marks at -20, -10, 0, 10, 20, 30, 40, 50, and 60.
* **Y-axis:** List of tasks. The tasks are:
* Boolean Expressionsλ
* Causal Judgement
* Date Understanding
* Disambiguation QA
* Dyck Languagesλ
* Formal Fallacies
* Geometric Shapesλ
* Hyperbaton
* Logical Deductionλ (avg)
* Movie Recommendation
* Multi Step Arithmeticλ [Two]
* Navigateλ
* Object Countingλ
* Penguins in a Table
* Reasoning about Colored Objects
* Ruin Names
* Salient Translation Error Detection
* Snarks
* Sports Understanding
* Temporal Sequencesλ
* Tracking Shuffled Objectsλ (avg)
* Web of Liesλ
* Word Sortingλ
* NLP Task (avg)
* Algorithmic Taskλ (avg)
* All Tasks (avg)
* **Legend:** Located in the bottom-right corner.
* Blue: InstructGPT (CoT) - InstructGPT (AO)
* Orange: Codex (CoT) - Codex (AO)
* Green: PaLM 540B (CoT) - PaLM 540B (AO)
* **Vertical Lines:**
* Dashed Black Line: Located at approximately x = 0.
* Dashed Green Line: Located at approximately x = 15.
* Dashed Gray Lines: Located at approximately x = 18 and x = 20.
### Detailed Analysis
* **InstructGPT (CoT - AO) - Blue:**
* Generally, the blue data points are clustered towards the right side of the plot, indicating that InstructGPT benefits from the Chain of Thought approach for most tasks.
* Specific points:
* Boolean Expressionsλ: ~35
* Causal Judgement: ~25
* Date Understanding: ~30
* Disambiguation QA: ~40
* Dyck Languagesλ: ~35
* Formal Fallacies: ~30
* Geometric Shapesλ: ~35
* Hyperbaton: ~40
* Logical Deductionλ (avg): ~35
* Movie Recommendation: ~35
* Multi Step Arithmeticλ [Two]: ~35
* Navigateλ: ~40
* Object Countingλ: ~40
* Penguins in a Table: ~30
* Reasoning about Colored Objects: ~35
* Ruin Names: ~35
* Salient Translation Error Detection: ~35
* Snarks: ~40
* Sports Understanding: ~40
* Temporal Sequencesλ: ~40
* Tracking Shuffled Objectsλ (avg): ~40
* Web of Liesλ: ~40
* Word Sortingλ: ~35
* NLP Task (avg): ~35
* Algorithmic Taskλ (avg): ~35
* All Tasks (avg): ~35
* **Codex (CoT - AO) - Orange:**
* The orange data points are more scattered, with some tasks showing a benefit from CoT and others showing little to no difference or even a slight decrease in accuracy.
* Specific points:
* Boolean Expressionsλ: ~-5
* Causal Judgement: ~10
* Date Understanding: ~10
* Disambiguation QA: ~10
* Dyck Languagesλ: ~10
* Formal Fallacies: ~10
* Geometric Shapesλ: ~10
* Hyperbaton: ~10
* Logical Deductionλ (avg): ~10
* Movie Recommendation: ~10
* Multi Step Arithmeticλ [Two]: ~10
* Navigateλ: ~10
* Object Countingλ: ~10
* Penguins in a Table: ~10
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequencesλ: ~10
* Tracking Shuffled Objectsλ (avg): ~10
* Web of Liesλ: ~10
* Word Sortingλ: ~10
* NLP Task (avg): ~10
* Algorithmic Taskλ (avg): ~10
* All Tasks (avg): ~10
* **PaLM 540B (CoT - AO) - Green:**
* The green data points are generally clustered between 0 and 20, suggesting a modest benefit from CoT for PaLM 540B.
* Specific points:
* Boolean Expressionsλ: ~10
* Causal Judgement: ~10
* Date Understanding: ~10
* Disambiguation QA: ~10
* Dyck Languagesλ: ~10
* Formal Fallacies: ~10
* Geometric Shapesλ: ~10
* Hyperbaton: ~10
* Logical Deductionλ (avg): ~10
* Movie Recommendation: ~10
* Multi Step Arithmeticλ [Two]: ~10
* Navigateλ: ~10
* Object Countingλ: ~10
* Penguins in a Table: ~10
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequencesλ: ~10
* Tracking Shuffled Objectsλ (avg): ~10
* Web of Liesλ: ~10
* Word Sortingλ: ~10
* NLP Task (avg): ~10
* Algorithmic Taskλ (avg): ~10
* All Tasks (avg): ~10
### Key Observations
* InstructGPT consistently benefits from the Chain of Thought approach across all tasks.
* Codex shows mixed results, with some tasks benefiting from CoT and others not.
* PaLM 540B shows a moderate benefit from CoT, generally less pronounced than InstructGPT.
* The "All Tasks (avg)" data points for each model reflect the general trend observed for the individual tasks.
### Interpretation
The data suggests that the effectiveness of the Chain of Thought approach varies significantly depending on the language model and the specific task. InstructGPT appears to be the most sensitive to the benefits of CoT, while Codex shows more task-dependent performance. PaLM 540B exhibits a more consistent, albeit less dramatic, improvement with CoT.
The vertical lines could represent thresholds or benchmarks for acceptable accuracy differences. The dashed black line at 0 indicates the point where CoT and AO have equal accuracy. The other lines may represent target accuracy improvements or significant performance differences.
The tasks themselves likely vary in complexity and the degree to which they benefit from explicit reasoning steps. Tasks with a higher "λ" symbol may be more amenable to the Chain of Thought approach. Further investigation into the nature of these tasks and the internal mechanisms of each language model would be needed to fully explain the observed differences.
DECODING INTELLIGENCE...