TECHNICAL ASSET FINGERPRINT
6872e0fc32baf49abecd26c1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
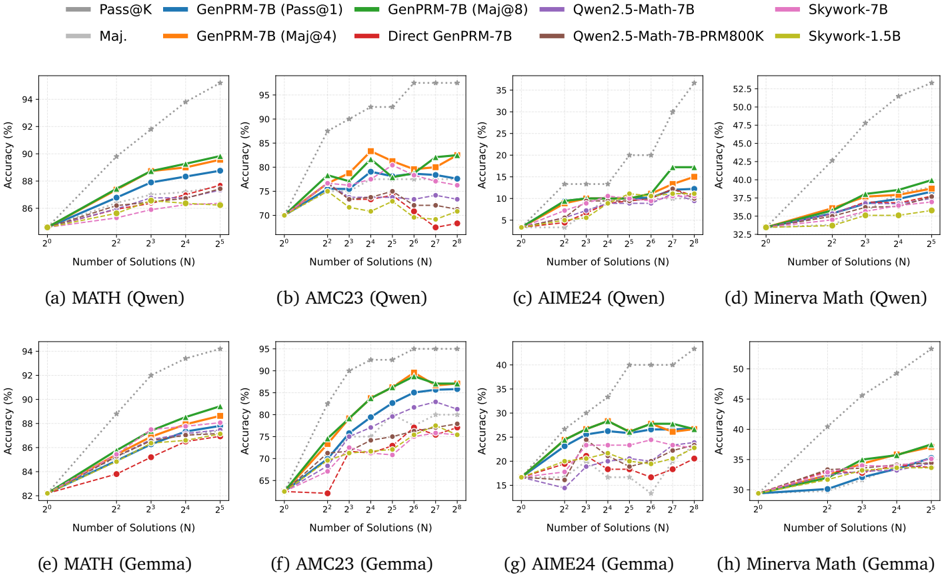
## Line Charts: Accuracy vs. Number of Solutions for Different Models
### Overview
The image presents eight line charts, arranged in a 2x4 grid, displaying the accuracy of various language models (Owen and Gemma) on four different math datasets: MATH, AMC23, AIME24, and Minerva Math. Accuracy is plotted against the number of solutions (N), ranging from 2<sup>2</sup> to 2<sup>5</sup> (4 to 32). Each chart focuses on a specific dataset and compares the performance of different model variants.
### Components/Axes
* **X-axis:** Number of Solutions (N), labeled as "Number of Solutions (N)". Scale: 4, 8, 16, 32.
* **Y-axis:** Accuracy (%), labeled as "Accuracy (%)". Scales vary per chart, but generally range from approximately 32% to 95%.
* **Legend:** Located at the top of the image, spanning all charts. The legend identifies the following models/metrics:
* Pass@K (Dark Blue)
* Maj. (Light Blue)
* GenPRM-7B (Pass@1) (Green)
* GenPRM-7B (Maj@8) (Orange)
* Qwen2.5-Math-7B (Red)
* Qwen2.5-Math-7B-PRM800K (Purple)
* Skywork-7B (Teal)
* Skywork-1.5B (Yellow)
* **Chart Titles:** Each chart is labeled with the dataset name and the model family (Owen or Gemma) in parentheses, e.g., "(a) MATH (Qwen)", "(f) AMC23 (Gemma)".
### Detailed Analysis or Content Details
**Chart (a) MATH (Qwen):**
* Pass@K: Starts at ~86%, increases to ~93% at N=32.
* Maj.: Starts at ~85%, increases to ~91% at N=32.
* GenPRM-7B (Pass@1): Starts at ~85%, increases to ~92% at N=32.
* GenPRM-7B (Maj@8): Starts at ~84%, increases to ~90% at N=32.
* Qwen2.5-Math-7B: Starts at ~86%, increases to ~93% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~85%, increases to ~92% at N=32.
* Skywork-7B: Starts at ~85%, increases to ~91% at N=32.
* Skywork-1.5B: Starts at ~84%, increases to ~90% at N=32.
**Chart (b) AMC23 (Qwen):**
* Pass@K: Starts at ~72%, increases to ~95% at N=32.
* Maj.: Starts at ~72%, increases to ~94% at N=32.
* GenPRM-7B (Pass@1): Starts at ~73%, increases to ~95% at N=32.
* GenPRM-7B (Maj@8): Starts at ~72%, increases to ~94% at N=32.
* Qwen2.5-Math-7B: Starts at ~73%, increases to ~95% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~72%, increases to ~94% at N=32.
* Skywork-7B: Starts at ~72%, increases to ~94% at N=32.
* Skywork-1.5B: Starts at ~71%, increases to ~93% at N=32.
**Chart (c) AIME24 (Qwen):**
* Pass@K: Starts at ~10%, increases to ~35% at N=32.
* Maj.: Starts at ~10%, increases to ~33% at N=32.
* GenPRM-7B (Pass@1): Starts at ~10%, increases to ~34% at N=32.
* GenPRM-7B (Maj@8): Starts at ~10%, increases to ~32% at N=32.
* Qwen2.5-Math-7B: Starts at ~12%, increases to ~35% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~11%, increases to ~33% at N=32.
* Skywork-7B: Starts at ~11%, increases to ~33% at N=32.
* Skywork-1.5B: Starts at ~10%, increases to ~32% at N=32.
**Chart (d) Minerva Math (Qwen):**
* Pass@K: Starts at ~33%, increases to ~50% at N=32.
* Maj.: Starts at ~33%, increases to ~48% at N=32.
* GenPRM-7B (Pass@1): Starts at ~33%, increases to ~49% at N=32.
* GenPRM-7B (Maj@8): Starts at ~33%, increases to ~47% at N=32.
* Qwen2.5-Math-7B: Starts at ~34%, increases to ~50% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~33%, increases to ~48% at N=32.
* Skywork-7B: Starts at ~33%, increases to ~47% at N=32.
* Skywork-1.5B: Starts at ~32%, increases to ~46% at N=32.
**Chart (e) MATH (Gemma):**
* Pass@K: Starts at ~84%, increases to ~94% at N=32.
* Maj.: Starts at ~83%, increases to ~92% at N=32.
* GenPRM-7B (Pass@1): Starts at ~84%, increases to ~93% at N=32.
* GenPRM-7B (Maj@8): Starts at ~83%, increases to ~91% at N=32.
* Qwen2.5-Math-7B: Starts at ~85%, increases to ~94% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~84%, increases to ~93% at N=32.
* Skywork-7B: Starts at ~84%, increases to ~92% at N=32.
* Skywork-1.5B: Starts at ~83%, increases to ~91% at N=32.
**Chart (f) AMC23 (Gemma):**
* Pass@K: Starts at ~70%, increases to ~95% at N=32.
* Maj.: Starts at ~69%, increases to ~94% at N=32.
* GenPRM-7B (Pass@1): Starts at ~71%, increases to ~95% at N=32.
* GenPRM-7B (Maj@8): Starts at ~70%, increases to ~94% at N=32.
* Qwen2.5-Math-7B: Starts at ~72%, increases to ~95% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~71%, increases to ~94% at N=32.
* Skywork-7B: Starts at ~70%, increases to ~94% at N=32.
* Skywork-1.5B: Starts at ~69%, increases to ~93% at N=32.
**Chart (g) AIME24 (Gemma):**
* Pass@K: Starts at ~15%, increases to ~40% at N=32.
* Maj.: Starts at ~15%, increases to ~38% at N=32.
* GenPRM-7B (Pass@1): Starts at ~16%, increases to ~39% at N=32.
* GenPRM-7B (Maj@8): Starts at ~15%, increases to ~37% at N=32.
* Qwen2.5-Math-7B: Starts at ~17%, increases to ~40% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~16%, increases to ~38% at N=32.
* Skywork-7B: Starts at ~16%, increases to ~38% at N=32.
* Skywork-1.5B: Starts at ~15%, increases to ~37% at N=32.
**Chart (h) Minerva Math (Gemma):**
* Pass@K: Starts at ~30%, increases to ~47% at N=32.
* Maj.: Starts at ~30%, increases to ~45% at N=32.
* GenPRM-7B (Pass@1): Starts at ~31%, increases to ~46% at N=32.
* GenPRM-7B (Maj@8): Starts at ~30%, increases to ~44% at N=32.
* Qwen2.5-Math-7B: Starts at ~32%, increases to ~47% at N=32.
* Qwen2.5-Math-7B-PRM800K: Starts at ~31%, increases to ~45% at N=32.
* Skywork-7B: Starts at ~31%, increases to ~44% at N=32.
* Skywork-1.5B: Starts at ~30%, increases to ~43% at N=32.
### Key Observations
* Accuracy generally increases with the number of solutions (N) across all datasets and models.
* The Qwen2.5-Math-7B model consistently performs at or near the top across all datasets.
* The Skywork-1.5B model generally exhibits the lowest accuracy.
* The AIME24 dataset consistently shows the lowest overall accuracy compared to the other datasets.
* The performance difference between the "Pass@K" and "Maj." metrics is minimal.
* The performance of the models is relatively similar between the Owen and Gemma families.
### Interpretation
The charts demonstrate the impact of increasing the number of solutions (N) on the accuracy of various language models in solving math problems. The consistent upward trend across all datasets suggests that providing more solutions improves the models' ability to arrive at the correct answer. The superior performance of the Qwen2.5-Math-7B model indicates its effectiveness in tackling these types of mathematical challenges. The lower accuracy on the AIME24 dataset suggests that this dataset presents a higher level of difficulty or requires different reasoning skills compared to the others. The relatively small differences between the models within each dataset suggest that the core architecture and training data play a significant role in performance, while the number of solutions acts as a supplementary factor. The consistent performance between the Owen and Gemma families suggests that the underlying model architecture is comparable, and the differences in performance are likely due to variations in training data or fine-tuning strategies.
DECODING INTELLIGENCE...