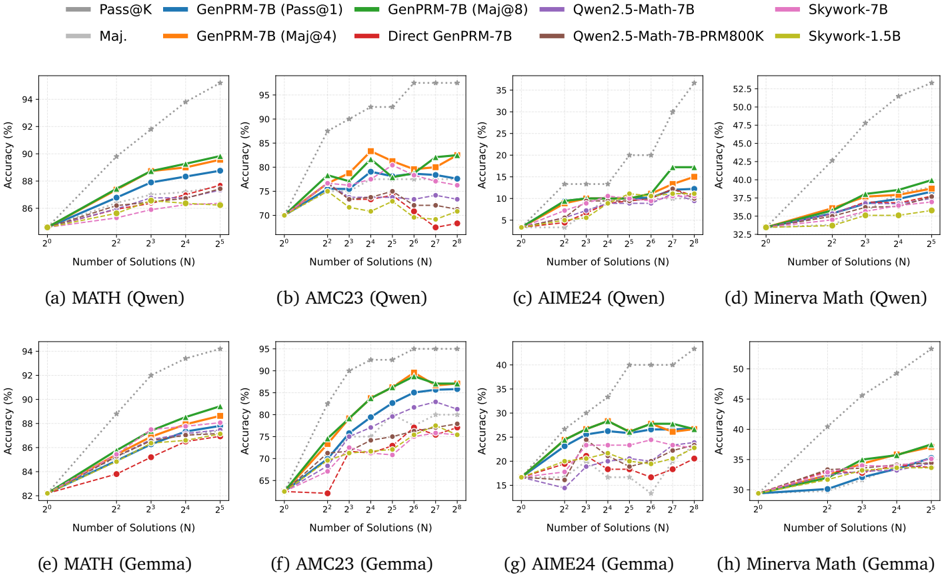
## Line Graphs: Model Accuracy vs. Number of Solutions Across Datasets
### Overview
The image contains eight line graphs comparing the accuracy of various AI models across four datasets (MATH, AMC23, AIME24, Minerva Math) as the number of solutions (N) increases. Each graph tests two problem sets (Qwen and Gemma) and evaluates models like Pass@K, GenPRM-7B variants, Direct GenPRM-7B, Qwen2.5-Math-7B, and Skywork models. Accuracy (%) is plotted against N (logarithmic scale: 2⁰ to 2⁸).
---
### Components/Axes
- **X-axis**: Number of Solutions (N) – Logarithmic scale (2⁰, 2¹, ..., 2⁸).
- **Y-axis**: Accuracy (%) – Ranges from ~30% to 95% depending on the dataset.
- **Legends**:
- **Colors**:
- Gray (dotted): Pass@K (baseline).
- Blue: GenPRM-7B (Pass@1).
- Green: GenPRM-7B (Maj@8).
- Orange: GenPRM-7B (Maj@4).
- Red: Direct GenPRM-7B.
- Purple: Qwen2.5-Math-7B.
- Pink: Skywork-7B.
- Brown: Qwen2.5-Math-7B-PRM800K.
- Yellow: Skywork-1.5B.
- **Placement**: Top-right corner of each graph.
---
### Detailed Analysis
#### (a) MATH (Qwen)
- **Trend**: Pass@K (gray dotted) slopes steeply upward (~85% at 2⁰ → ~94% at 2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) starts at ~85% (2⁰) and reaches ~90% (2⁸).
- GenPRM-7B (Maj@8, green) peaks at ~91% (2⁸).
- Direct GenPRM-7B (red dashed) lags behind, peaking at ~88% (2⁸).
- **Key**: Pass@K dominates; GenPRM-7B variants improve with N.
#### (b) AMC23 (Qwen)
- **Trend**: Pass@K rises from ~70% (2⁰) to ~95% (2⁸).
- **Models**:
- GenPRM-7B (Maj@4, orange) peaks at ~88% (2⁶) then declines slightly.
- Qwen2.5-Math-7B (purple) stabilizes at ~85% (2⁸).
- **Key**: Maj@4 configuration underperforms at higher N.
#### (c) AIME24 (Qwen)
- **Trend**: Pass@K increases from ~35% (2⁰) to ~52% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~42% (2⁸).
- Skywork-7B (pink) peaks at ~38% (2⁸).
- **Key**: All models lag Pass@K; Skywork-7B performs better than GenPRM-7B.
#### (d) Minerva Math (Qwen)
- **Trend**: Pass@K rises from ~32% (2⁰) to ~53% (2⁸).
- **Models**:
- GenPRM-7B (Maj@8, green) peaks at ~42% (2⁸).
- Qwen2.5-Math-7B-PRM800K (brown) stabilizes at ~38% (2⁸).
- **Key**: Maj@8 configuration outperforms others.
#### (e) MATH (Gemma)
- **Trend**: Pass@K rises from ~82% (2⁰) to ~94% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~89% (2⁸).
- Skywork-1.5B (yellow) peaks at ~87% (2⁸).
- **Key**: Skywork-1.5B closely matches GenPRM-7B.
#### (f) AMC23 (Gemma)
- **Trend**: Pass@K increases from ~65% (2⁰) to ~95% (2⁸).
- **Models**:
- GenPRM-7B (Maj@4, orange) peaks at ~85% (2⁶) then drops.
- Qwen2.5-Math-7B (purple) stabilizes at ~80% (2⁸).
- **Key**: Maj@4 configuration shows overfitting.
#### (g) AIME24 (Gemma)
- **Trend**: Pass@K rises from ~15% (2⁰) to ~40% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~35% (2⁸).
- Skywork-7B (pink) peaks at ~32% (2⁸).
- **Key**: Skywork-7B slightly outperforms GenPRM-7B.
#### (h) Minerva Math (Gemma)
- **Trend**: Pass@K increases from ~30% (2⁰) to ~50% (2⁸).
- **Models**:
- GenPRM-7B (Maj@8, green) peaks at ~40% (2⁸).
- Skywork-1.5B (yellow) stabilizes at ~37% (2⁸).
- **Key**: Maj@8 configuration leads.
---
### Key Observations
1. **Pass@K Baseline**: Consistently outperforms all models across datasets.
2. **Model Variants**:
- GenPRM-7B (Maj@8) generally performs better than Pass@1 or Maj@4.
- Direct GenPRM-7B (red dashed) underperforms variants.
3. **Diminishing Returns**: Some models (e.g., GenPRM-7B Maj@4 in AMC23) plateau or decline at higher N.
4. **Skywork Models**: Competitive with GenPRM-7B in MATH and AIME24 but lag in AMC23.
---
### Interpretation
- **Scalability**: Increasing N improves accuracy, but gains diminish as N grows (e.g., AMC23 Qwen).
- **Model Efficiency**: GenPRM-7B variants with majority voting (Maj@8) often outperform simpler configurations.
- **Dataset-Specific Behavior**:
- AIME24 (high-difficulty math) shows the largest gap between models and Pass@K.
- Minerva Math (reasoning-focused) benefits more from majority voting.
- **Anomalies**:
- Direct GenPRM-7B (red dashed) consistently underperforms, suggesting architectural limitations.
- Skywork-1.5B matches GenPRM-7B in MATH but struggles in AMC23, indicating dataset-specific weaknesses.
This analysis highlights the trade-offs between model complexity, voting strategies, and dataset characteristics in solving math problems.