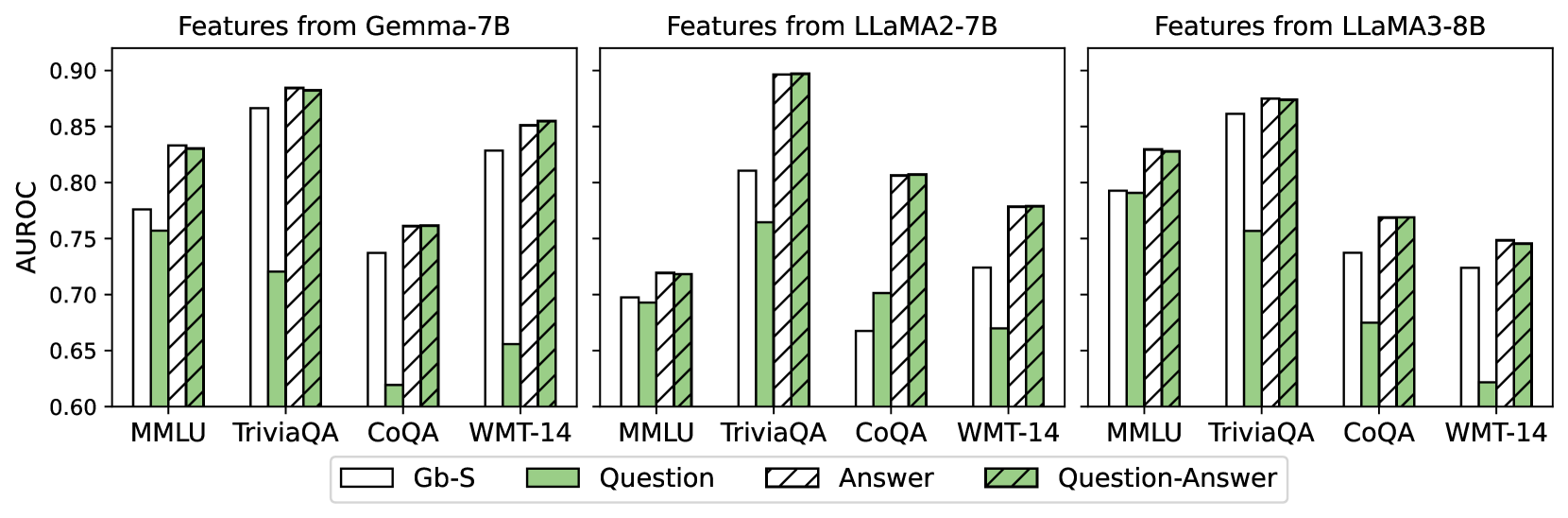
## Bar Chart: AUROC Comparison Across Models and Datasets
### Overview
The image is a grouped bar chart comparing the Area Under the Receiver Operating Characteristic curve (AUROC) values for different feature combinations across three language models (Gemma-7B, LLaMA2-7B, LLaMA3-8B) and four datasets (MMLU, TriviaQA, CoQA, WMT-14). The chart uses four feature types: Gb-S (white), Question (green), Answer (striped), and Question-Answer (green with diagonal lines).
### Components/Axes
- **X-axis**: Datasets (MMLU, TriviaQA, CoQA, WMT-14), repeated for each model.
- **Y-axis**: AUROC values (0.6–0.9), labeled "AUROC".
- **Legend**: Located at the bottom, with four categories:
- Gb-S (solid white)
- Question (solid green)
- Answer (striped white/green)
- Question-Answer (green with diagonal lines)
- **Model Groups**: Three vertical clusters labeled "Features from Gemma-7B", "Features from LLaMA2-7B", and "Features from LLaMA3-8B".
### Detailed Analysis
#### Gemma-7B
- **MMLU**:
- Gb-S: ~0.78
- Question: ~0.76
- Answer: ~0.83
- Question-Answer: ~0.83
- **TriviaQA**:
- Gb-S: ~0.87
- Question: ~0.72
- Answer: ~0.89
- Question-Answer: ~0.89
- **CoQA**:
- Gb-S: ~0.74
- Question: ~0.62
- Answer: ~0.76
- Question-Answer: ~0.76
- **WMT-14**:
- Gb-S: ~0.83
- Question: ~0.65
- Answer: ~0.85
- Question-Answer: ~0.85
#### LLaMA2-7B
- **MMLU**:
- Gb-S: ~0.70
- Question: ~0.70
- Answer: ~0.72
- Question-Answer: ~0.72
- **TriviaQA**:
- Gb-S: ~0.81
- Question: ~0.77
- Answer: ~0.90
- Question-Answer: ~0.90
- **CoQA**:
- Gb-S: ~0.66
- Question: ~0.70
- Answer: ~0.81
- Question-Answer: ~0.81
- **WMT-14**:
- Gb-S: ~0.73
- Question: ~0.67
- Answer: ~0.78
- Question-Answer: ~0.78
#### LLaMA3-8B
- **MMLU**:
- Gb-S: ~0.79
- Question: ~0.79
- Answer: ~0.83
- Question-Answer: ~0.83
- **TriviaQA**:
- Gb-S: ~0.86
- Question: ~0.76
- Answer: ~0.88
- Question-Answer: ~0.88
- **CoQA**:
- Gb-S: ~0.74
- Question: ~0.68
- Answer: ~0.77
- Question-Answer: ~0.77
- **WMT-14**:
- Gb-S: ~0.73
- Question: ~0.62
- Answer: ~0.75
- Question-Answer: ~0.75
### Key Observations
1. **Question-Answer Feature Dominance**:
- The Question-Answer feature (green with diagonal lines) consistently achieves the highest AUROC across all models and datasets, often matching or slightly exceeding the Answer feature (striped).
- Example: LLaMA2-7B on TriviaQA shows Question-Answer at 0.90, the highest value in the chart.
2. **Gb-S Variability**:
- Gb-S (solid white) performs inconsistently. It outperforms other features in Gemma-7B's TriviaQA (0.87) but underperforms in LLaMA2-7B's MMLU (0.70).
3. **Dataset-Specific Trends**:
- **TriviaQA**: All models show strong performance, with AUROC values clustering near 0.85–0.90.
- **WMT-14**: Lowest performance across all models, with AUROC values generally below 0.80.
- **CoQA**: Mixed results, with Question-Answer often matching Answer feature performance.
4. **Model Performance**:
- LLaMA3-8B generally outperforms Gemma-7B and LLaMA2-7B, particularly in TriviaQA and MMLU.
- Gemma-7B shows the highest Gb-S performance in TriviaQA (0.87).
### Interpretation
The data suggests that **combining question and answer features (Question-Answer)** yields the most robust performance across models and datasets, likely due to richer contextual information. The Gb-S feature's inconsistent results imply it may be less effective or model-dependent. TriviaQA and MMLU datasets appear more amenable to feature-based improvements, while WMT-14's lower performance might reflect task-specific challenges (e.g., translation vs. QA). The Answer feature alone often bridges the gap between Gb-S and Question-Answer, highlighting its utility as a standalone feature. Model architecture differences (e.g., LLaMA3-8B's larger size) may explain performance variations, though the chart does not explicitly test this hypothesis.