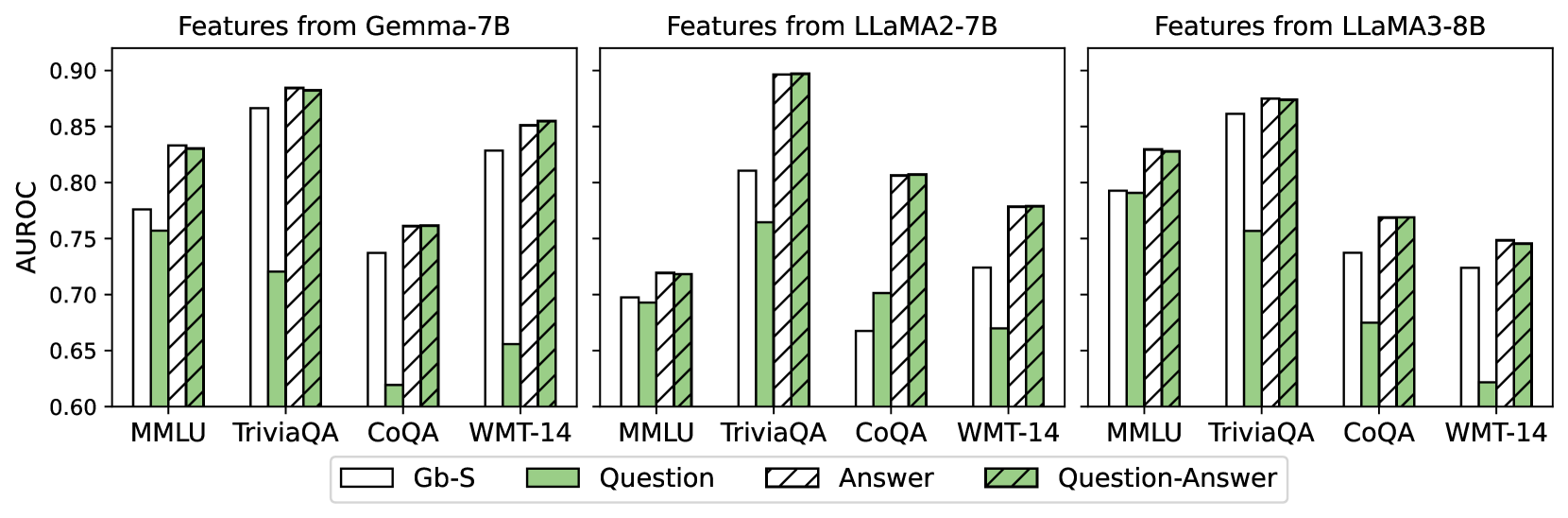
## Bar Chart: Features from Gemma-7B, LLAMA2-7B, and LLAMA3-8B
### Overview
The image presents three bar charts comparing the AUROC scores of different features extracted from three language models: Gemma-7B, LLAMA2-7B, and LLAMA3-8B. Each chart displays the AUROC scores for four tasks (MMLU, TriviaQA, CoQA, and WMT-14) across three feature types: Gb-S, Question, and Question-Answer.
### Components/Axes
* **Title:** Features from Gemma-7B (left), Features from LLAMA2-7B (center), Features from LLAMA3-8B (right)
* **Y-axis:** AUROC, ranging from 0.60 to 0.90 in increments of 0.05.
* **X-axis:** Categorical, representing the tasks: MMLU, TriviaQA, CoQA, WMT-14.
* **Legend:** Located at the bottom of the chart.
* Gb-S: White bars
* Question: Light green bars
* Answer: White bars with black diagonal stripes
* Question-Answer: Light green bars with black diagonal stripes
### Detailed Analysis
**Chart 1: Features from Gemma-7B**
* **MMLU:**
* Gb-S: ~0.78
* Question: ~0.76
* Question-Answer: ~0.83
* **TriviaQA:**
* Gb-S: ~0.87
* Question: ~0.72
* Question-Answer: ~0.89
* **CoQA:**
* Gb-S: ~0.74
* Question: ~0.76
* Question-Answer: ~0.77
* **WMT-14:**
* Gb-S: ~0.66
* Question: ~0.85
* Question-Answer: ~0.86
**Chart 2: Features from LLAMA2-7B**
* **MMLU:**
* Gb-S: ~0.72
* Question: ~0.70
* Question-Answer: ~0.73
* **TriviaQA:**
* Gb-S: ~0.81
* Question: ~0.77
* Question-Answer: ~0.90
* **CoQA:**
* Gb-S: ~0.62
* Question: ~0.67
* Question-Answer: ~0.79
* **WMT-14:**
* Gb-S: ~0.78
* Question: ~0.78
* Question-Answer: ~0.80
**Chart 3: Features from LLAMA3-8B**
* **MMLU:**
* Gb-S: ~0.78
* Question: ~0.79
* Question-Answer: ~0.83
* **TriviaQA:**
* Gb-S: ~0.86
* Question: ~0.72
* Question-Answer: ~0.88
* **CoQA:**
* Gb-S: ~0.72
* Question: ~0.77
* Question-Answer: ~0.78
* **WMT-14:**
* Gb-S: ~0.73
* Question: ~0.75
* Question-Answer: ~0.75
### Key Observations
* For all three models, TriviaQA generally yields the highest AUROC scores, especially for the Question-Answer feature.
* CoQA tends to have the lowest AUROC scores across all models and feature types.
* The Question-Answer feature generally performs better than the Question feature, and both are often better than Gb-S.
* LLAMA2-7B shows a particularly low AUROC score for CoQA across all feature types.
### Interpretation
The charts compare the performance of different features extracted from three language models on various tasks, as measured by AUROC. The results suggest that the type of feature used significantly impacts performance, with Question-Answer features generally outperforming Gb-S and Question features. The models also exhibit varying levels of success across different tasks, indicating that some tasks are inherently more challenging or better suited to the models' capabilities. The relatively low performance on CoQA across all models suggests that this task may require different or more sophisticated features. The high performance on TriviaQA, especially with Question-Answer features, indicates that these models are particularly adept at answering trivia questions when provided with both the question and answer information.