TECHNICAL ASSET FINGERPRINT
68f7f61ba46f120af21384f6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
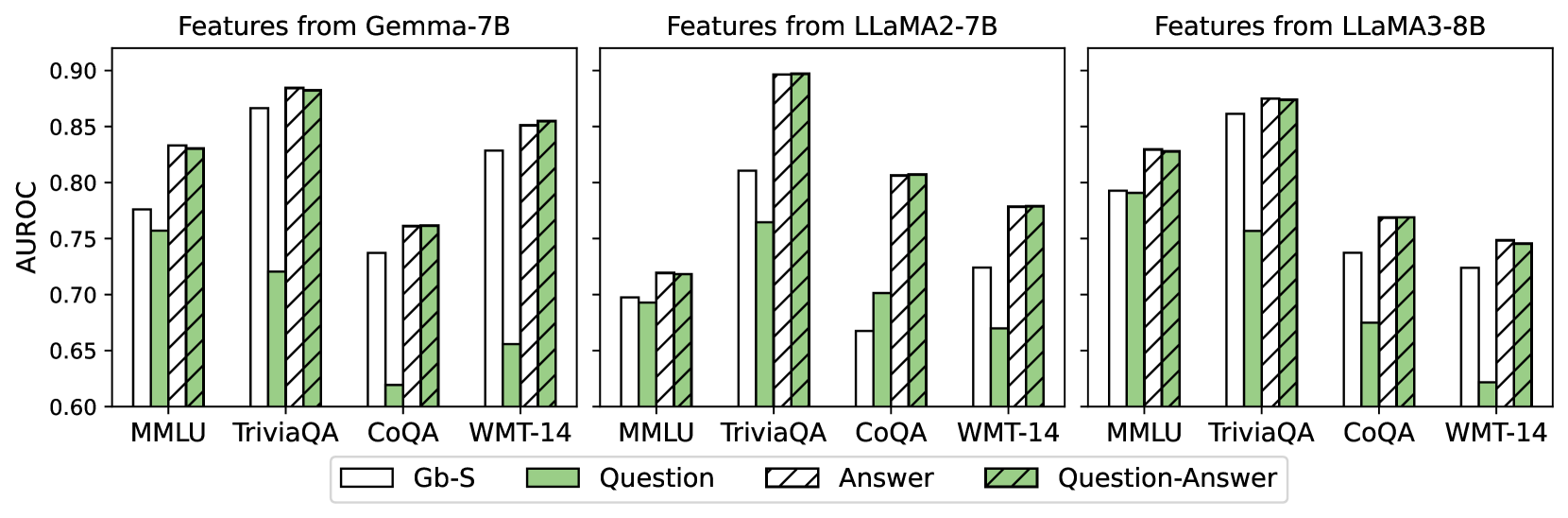
## Bar Chart: AUROC Performance of Different Feature Types Across Language Models and Tasks
### Overview
The image displays a set of three grouped bar charts comparing the AUROC (Area Under the Receiver Operating Characteristic curve) performance of four different feature types ("Gb-S", "Question", "Answer", "Question-Answer") extracted from three different large language models (Gemma-7B, LLaMA2-7B, LLaMA3-8B). The performance is evaluated across four distinct tasks or datasets: MMLU, TriviaQA, CoQA, and WMT-14.
### Components/Axes
* **Main Titles (Top of each subplot):**
* Left: "Features from Gemma-7B"
* Center: "Features from LLaMA2-7B"
* Right: "Features from LLaMA3-8B"
* **Y-Axis (Common to all subplots):**
* Label: "AUROC"
* Scale: Linear, ranging from 0.60 to 0.90, with major tick marks at 0.05 intervals (0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90).
* **X-Axis (Within each subplot):**
* Categories (from left to right): "MMLU", "TriviaQA", "CoQA", "WMT-14".
* **Legend (Centered at the bottom of the entire figure):**
* **Gb-S:** Represented by a white bar with a black outline.
* **Question:** Represented by a solid light green bar.
* **Answer:** Represented by a white bar with diagonal black hatching (\\).
* **Question-Answer:** Represented by a light green bar with diagonal black hatching (\\).
### Detailed Analysis
The analysis is segmented by subplot (model) and then by task category. Values are approximate visual estimates from the chart.
**1. Features from Gemma-7B (Left Subplot)**
* **MMLU:**
* Gb-S: ~0.78
* Question: ~0.76
* Answer: ~0.83
* Question-Answer: ~0.83
* *Trend:* Answer and Question-Answer features perform similarly and are highest, followed by Gb-S, then Question.
* **TriviaQA:**
* Gb-S: ~0.87
* Question: ~0.72
* Answer: ~0.88
* Question-Answer: ~0.88
* *Trend:* Answer and Question-Answer are highest and nearly identical. Gb-S is slightly lower. Question is the lowest by a significant margin.
* **CoQA:**
* Gb-S: ~0.74
* Question: ~0.62
* Answer: ~0.76
* Question-Answer: ~0.76
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is next. Question is the lowest.
* **WMT-14:**
* Gb-S: ~0.83
* Question: ~0.66
* Answer: ~0.85
* Question-Answer: ~0.85
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is slightly lower. Question is the lowest.
**2. Features from LLaMA2-7B (Center Subplot)**
* **MMLU:**
* Gb-S: ~0.70
* Question: ~0.69
* Answer: ~0.72
* Question-Answer: ~0.72
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S and Question are very close and lower.
* **TriviaQA:**
* Gb-S: ~0.81
* Question: ~0.77
* Answer: ~0.90
* Question-Answer: ~0.90
* *Trend:* Answer and Question-Answer are highest and equal, reaching the top of the scale. Gb-S is next, followed by Question.
* **CoQA:**
* Gb-S: ~0.67
* Question: ~0.70
* Answer: ~0.81
* Question-Answer: ~0.81
* *Trend:* Answer and Question-Answer are highest and equal. Question is next, followed by Gb-S.
* **WMT-14:**
* Gb-S: ~0.73
* Question: ~0.67
* Answer: ~0.78
* Question-Answer: ~0.78
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is next, followed by Question.
**3. Features from LLaMA3-8B (Right Subplot)**
* **MMLU:**
* Gb-S: ~0.79
* Question: ~0.79
* Answer: ~0.83
* Question-Answer: ~0.83
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S and Question are very close and lower.
* **TriviaQA:**
* Gb-S: ~0.86
* Question: ~0.76
* Answer: ~0.88
* Question-Answer: ~0.88
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is next, followed by Question.
* **CoQA:**
* Gb-S: ~0.74
* Question: ~0.68
* Answer: ~0.77
* Question-Answer: ~0.77
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is next, followed by Question.
* **WMT-14:**
* Gb-S: ~0.73
* Question: ~0.62
* Answer: ~0.75
* Question-Answer: ~0.75
* *Trend:* Answer and Question-Answer are highest and equal. Gb-S is next, followed by Question.
### Key Observations
1. **Consistent Superiority of Answer-Based Features:** Across all three models and all four tasks, the "Answer" and "Question-Answer" feature types consistently achieve the highest AUROC scores. Their performance is virtually identical in every single case.
2. **Performance of Gb-S and Question Features:** The "Gb-S" and "Question" features generally perform worse than the answer-inclusive features. The "Question" feature is frequently the lowest-performing, with a notable exception in LLaMA2-7B's CoQA task where it outperforms Gb-S.
3. **Task Difficulty Variation:** The absolute AUROC values vary by task. For example, performance on TriviaQA tends to be higher (often >0.85 for top features) compared to CoQA or WMT-14, suggesting differences in task difficulty or the suitability of the features for those tasks.
4. **Model Comparison:** While all models show the same general pattern, the absolute performance levels differ. For instance, LLaMA2-7B achieves the highest single score (~0.90 on TriviaQA with Answer/QA features), while its performance on MMLU is the lowest among the three models for that task.
### Interpretation
This chart investigates the efficacy of different textual feature types (derived from questions, answers, or both) for some downstream evaluation metric (measured by AUROC) across various language models and benchmarks.
The central finding is that **features incorporating the "Answer" component—either alone or combined with the "Question"—are significantly more informative or predictive** than features based solely on the "Question" or the baseline "Gb-S" (which likely represents a different, perhaps model-internal, feature set). The identical performance of "Answer" and "Question-Answer" features suggests that adding the question to the answer provides no marginal benefit for this specific evaluation metric; the answer text alone carries the critical signal.
This implies that for the tasks evaluated (MMLU, TriviaQA, CoQA, WMT-14), the model's generated or retrieved answer contains the most discriminative information. The question text, while necessary to prompt the model, does not contribute additional predictive power once the answer is available. The "Gb-S" features serve as a middle-ground baseline, often outperforming pure "Question" features but falling short of answer-based ones.
The consistency of this pattern across three distinct model architectures (Gemma, LLaMA2, LLaMA3) strengthens the conclusion that this is a robust phenomenon related to the nature of the tasks and the information content of answers versus questions, rather than an artifact of a specific model.
DECODING INTELLIGENCE...