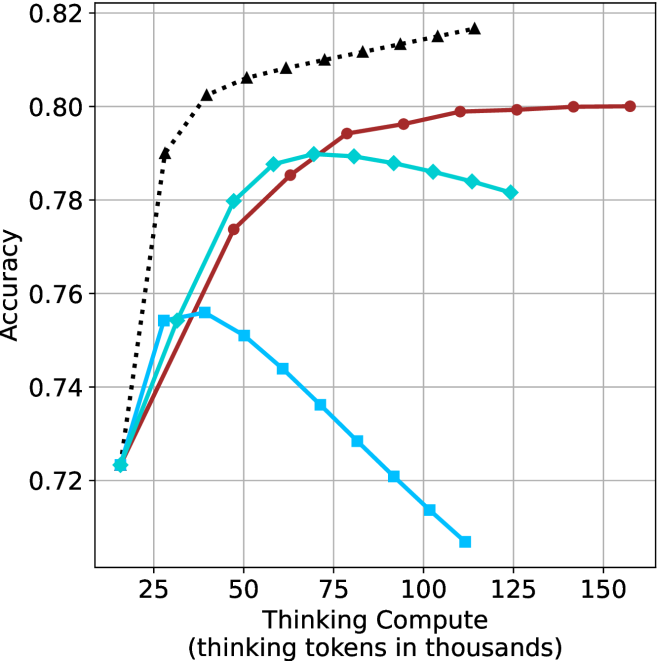
## Line Chart: Accuracy vs. Thinking Compute (Tokens in Thousands)
### Overview
The chart compares the accuracy of three computational methods across varying levels of "Thinking Compute" (measured in thousands of thinking tokens). Three data series are plotted:
1. **Red line**: "Thinking Compute"
2. **Teal line**: "Thinking Compute + Prompting"
3. **Blue line**: "Thinking Compute + Prompting + Chain-of-Thought"
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Scale: 25 to 150 (increments of 25)
- Labels: 25, 50, 75, 100, 125, 150
- **Y-axis**: "Accuracy"
- Scale: 0.72 to 0.82 (increments of 0.02)
- Labels: 0.72, 0.74, 0.76, 0.78, 0.80, 0.82
- **Legend**: Located on the right side of the chart.
- Colors:
- Red: "Thinking Compute"
- Teal: "Thinking Compute + Prompting"
- Blue: "Thinking Compute + Prompting + Chain-of-Thought"
### Detailed Analysis
1. **Red Line ("Thinking Compute")**:
- Starts at **0.72** (x=25) and increases steadily to **0.80** (x=150).
- Key points:
- x=50: ~0.76
- x=75: ~0.78
- x=100: ~0.79
- x=125: ~0.80
- x=150: ~0.80
2. **Teal Line ("Thinking Compute + Prompting")**:
- Starts at **0.72** (x=25), peaks at **0.79** (x=75), then declines slightly.
- Key points:
- x=50: ~0.78
- x=100: ~0.78
- x=125: ~0.78
- x=150: ~0.78
3. **Blue Line ("Thinking Compute + Prompting + Chain-of-Thought")**:
- Starts at **0.72** (x=25), peaks at **0.76** (x=50), then declines sharply.
- Key points:
- x=75: ~0.74
- x=100: ~0.73
- x=125: ~0.72
- x=150: ~0.71
### Key Observations
- **Red line** (baseline method) shows consistent improvement with increased compute.
- **Teal line** (prompting) achieves higher accuracy than the baseline but plateaus after x=75.
- **Blue line** (chain-of-thought) initially outperforms the baseline but degrades significantly at higher compute levels.
- All methods converge near **0.72–0.78** accuracy at x=25, but diverge as compute increases.
### Interpretation
The data suggests that **increasing compute improves accuracy** for all methods, but the benefits diminish with added complexity:
- **Prompting** (teal) provides a moderate boost but becomes less effective beyond 75k tokens.
- **Chain-of-thought** (blue) initially enhances performance but suffers from **overfitting or inefficiency** at scale, leading to a sharp decline.
- The **baseline method** (red) remains the most stable and scalable, achieving the highest accuracy (0.80) at maximum compute.
This implies that while advanced techniques like prompting and chain-of-thought can enhance performance, their effectiveness is context-dependent and may not scale linearly with compute resources.