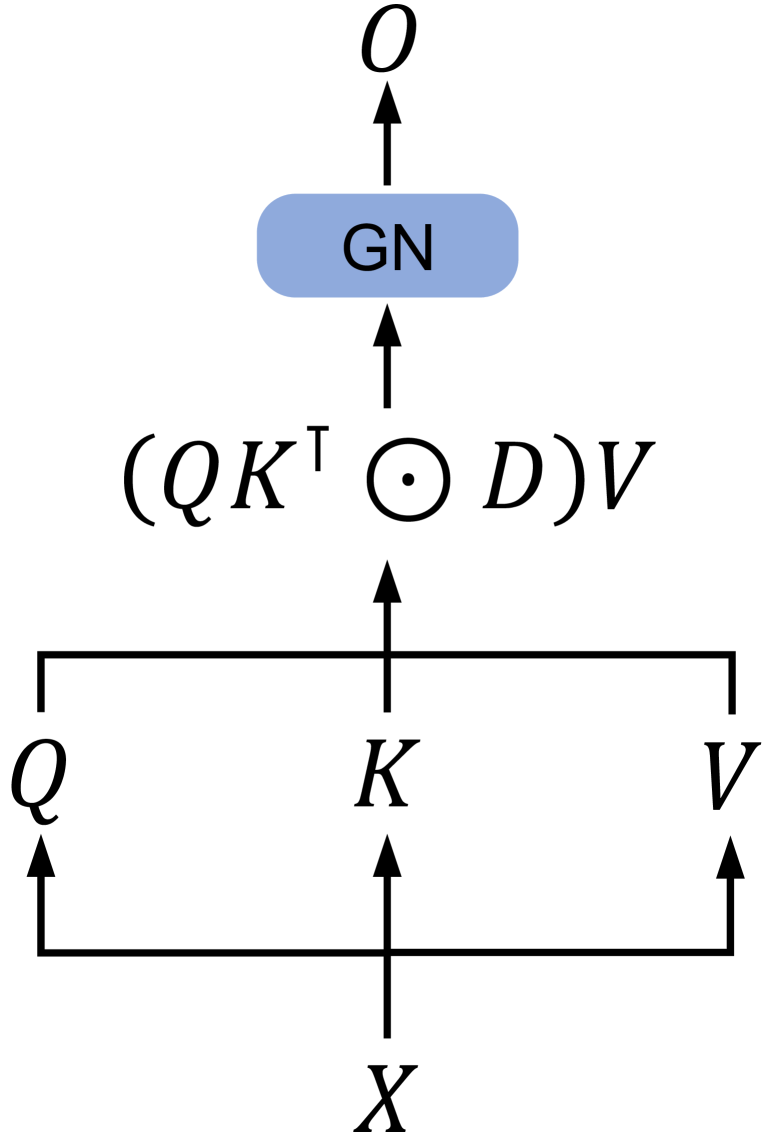
## Diagram: Computational Graph with Matrix Operations
### Overview
The diagram illustrates a computational graph with labeled nodes and directional arrows indicating data flow or dependencies. Key elements include mathematical operations, matrix transpositions, and a labeled block ("GN"). The structure suggests a hierarchical or layered system, possibly related to machine learning or linear algebra.
### Components/Axes
- **Nodes**:
- **O**: Topmost node with an upward arrow.
- **GN**: Blue rectangular block labeled "GN" (likely an abbreviation for a component like "Generator Network" or "Gated Network").
- **(QKᵀ ⊙ D)V**: Mathematical expression below GN, involving:
- **QKᵀ**: Transpose of matrix K multiplied by Q.
- **⊙ D**: Element-wise (Hadamard) product with matrix D.
- **V**: Final multiplication by matrix V.
- **Q, K, V**: Three horizontally aligned nodes with upward arrows pointing to **X**.
- **X**: Bottom node receiving inputs from Q, K, and V.
- **Arrows**:
- Vertical arrows connect **O → GN → (QKᵀ ⊙ D)V**.
- Horizontal arrows connect **Q → K → V**.
- Vertical arrows from **Q, K, V → X**.
### Detailed Analysis
1. **Mathematical Operations**:
- The expression **(QKᵀ ⊙ D)V** implies:
- **QKᵀ**: Matrix multiplication of Q and the transpose of K.
- **⊙ D**: Element-wise multiplication with D (common in attention mechanisms).
- **V**: Final scaling or transformation by V.
- This resembles operations in transformer models (e.g., scaled dot-product attention).
2. **Flow Structure**:
- **O** is the output, dependent on **GN**, which processes the result of **(QKᵀ ⊙ D)V**.
- **Q, K, V** are inputs to **X**, suggesting a parallel processing pathway.
- **X** aggregates inputs from Q, K, and V, possibly representing a combined feature or output.
### Key Observations
- The diagram lacks numerical values, focusing instead on symbolic relationships.
- The use of **Q, K, V** aligns with attention mechanisms in NLP or vision transformers.
- **GN** acts as an intermediary block, potentially modifying or routing data between layers.
### Interpretation
This diagram likely represents a simplified architecture of a neural network layer, such as a transformer's attention mechanism. The **GN** block could be a gating unit (e.g., Gated Linear Unit) or a generator component. The operations **(QKᵀ ⊙ D)V** suggest attention scoring (QKᵀ), scaling (D), and value aggregation (V). The parallel flow from **Q, K, V → X** might indicate feature fusion or multi-path processing. The absence of numerical data implies this is a conceptual or symbolic representation rather than a data-driven chart.