TECHNICAL ASSET FINGERPRINT
697a2c3eebc255e155025d2d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
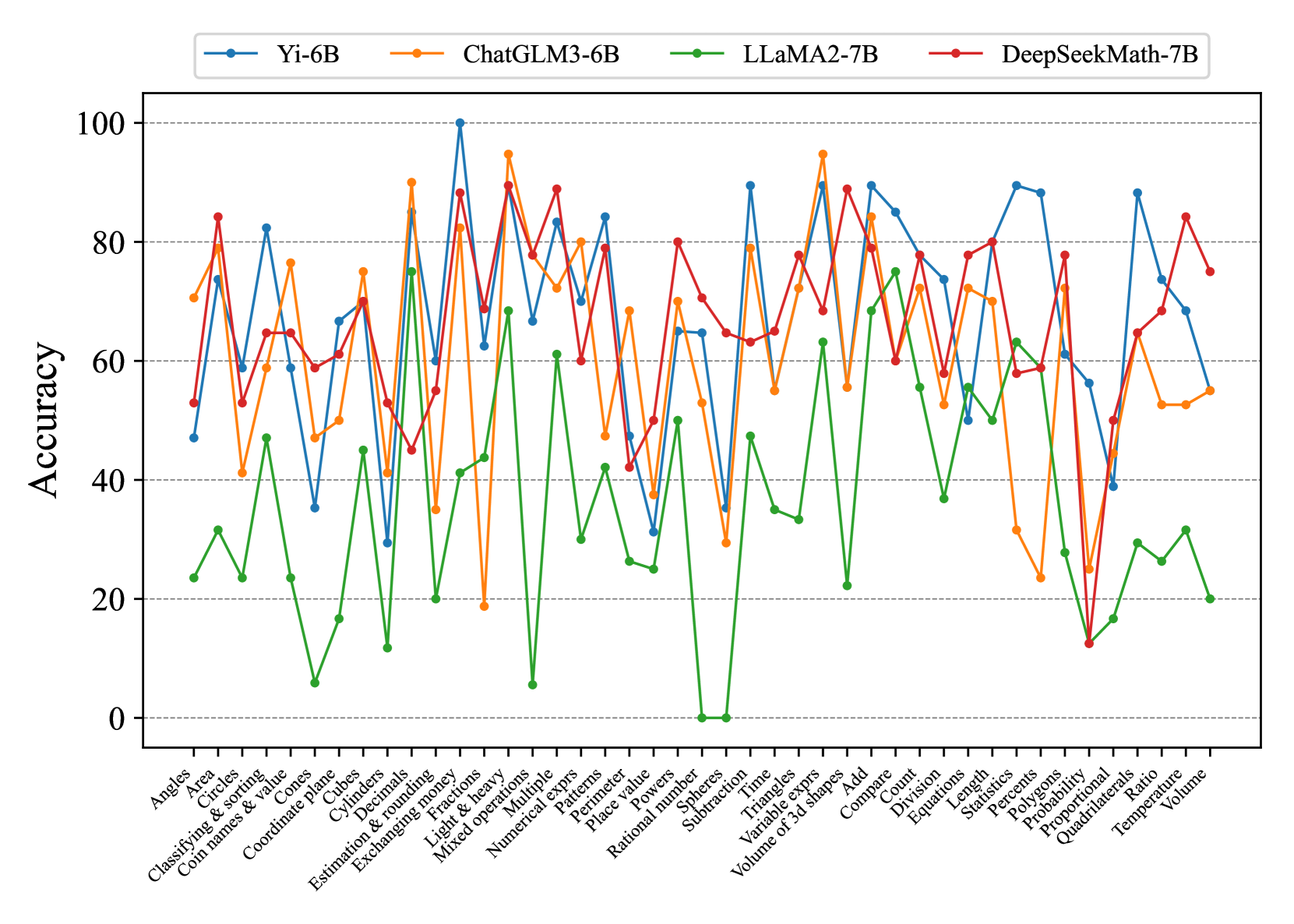
## Line Chart: Math Problem Accuracy by Model
### Overview
This line chart compares the accuracy of four large language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) on a variety of math problems. The x-axis represents different math problem types, and the y-axis represents the accuracy score, ranging from 0 to 100. The chart displays the performance of each model as a line, allowing for a visual comparison of their strengths and weaknesses across different problem categories.
### Components/Axes
* **X-axis Title:** Math Problem Types
* **Y-axis Title:** Accuracy
* **Y-axis Scale:** 0 to 100, with increments of 10.
* **Legend:** Located at the top-center of the chart.
* Yi-6B (Blue Line)
* ChatGLM3-6B (Magenta Line)
* LLaMA2-7B (Green Line)
* DeepSeekMath-7B (Red Line)
* **X-axis Labels (Math Problem Types):** Angles, Area, Classifying & sorting, Coil names & value, Coordinate plane, Cubes, Decimals, Estimation & rounding, Exchanging money, Fractions, Light & heavy, Mixed operations, Numerical Multiple, Patterns, Place value, Rational numbers, Sphere, Subtraction, Spheres, Time, Triangles, Add, Combinations, Count, Division, Equations, Length, Pentagons, Percentages, Probability, Proportional, Quadrilaterals, Ratio, Temperature, Volume.
### Detailed Analysis
Here's a breakdown of each model's performance, based on the visual trends and approximate data points:
* **Yi-6B (Blue Line):** This line exhibits significant fluctuations. It starts around 70, dips to approximately 50 for "Cubes", rises to a peak of around 95 for "Fractions", then declines again, ending around 80.
* **ChatGLM3-6B (Magenta Line):** This line generally stays between 60 and 80, with a peak around 85 for "Patterns". It shows a relatively stable performance across most problem types, with a slight dip around 60 for "Volume".
* **LLaMA2-7B (Green Line):** This model starts very low, around 20-30, and gradually increases to a peak of around 90 for "Triangles". It then declines, ending around 60-70. This model shows the most significant improvement in accuracy as the problem types progress.
* **DeepSeekMath-7B (Red Line):** This line starts high, around 80-90, and then declines sharply to a low of around 20-30 for "Volume". It shows a generally decreasing trend in accuracy as the problem types progress.
**Specific Data Points (Approximate):**
| Problem Type | Yi-6B | ChatGLM3-6B | LLaMA2-7B | DeepSeekMath-7B |
| ------------------- | ----- | ----------- | --------- | --------------- |
| Angles | 70 | 75 | 30 | 85 |
| Area | 75 | 70 | 40 | 80 |
| Classifying & sorting| 70 | 65 | 50 | 75 |
| Coil names & value | 65 | 60 | 55 | 70 |
| Coordinate plane | 70 | 70 | 60 | 75 |
| Cubes | 50 | 65 | 60 | 70 |
| Decimals | 75 | 70 | 65 | 75 |
| Estimation & rounding| 80 | 75 | 70 | 80 |
| Exchanging money | 80 | 75 | 75 | 80 |
| Fractions | 95 | 80 | 80 | 85 |
| Light & heavy | 80 | 75 | 70 | 80 |
| Mixed operations | 75 | 70 | 75 | 75 |
| Numerical Multiple | 70 | 65 | 70 | 70 |
| Patterns | 75 | 85 | 75 | 75 |
| Place value | 70 | 70 | 70 | 70 |
| Rational numbers | 70 | 65 | 70 | 65 |
| Sphere | 70 | 70 | 70 | 70 |
| Subtraction | 70 | 70 | 70 | 70 |
| Spheres | 70 | 70 | 70 | 70 |
| Time | 70 | 70 | 70 | 70 |
| Triangles | 80 | 75 | 90 | 75 |
| Add | 85 | 80 | 80 | 80 |
| Combinations | 80 | 75 | 75 | 75 |
| Count | 80 | 75 | 70 | 70 |
| Division | 75 | 70 | 65 | 65 |
| Equations | 70 | 65 | 60 | 60 |
| Length | 70 | 65 | 60 | 60 |
| Pentagons | 70 | 65 | 55 | 55 |
| Percentages | 70 | 65 | 50 | 50 |
| Probability | 70 | 65 | 45 | 45 |
| Proportional | 75 | 70 | 40 | 40 |
| Quadrilaterals | 75 | 70 | 35 | 35 |
| Ratio | 80 | 75 | 30 | 30 |
| Temperature | 80 | 75 | 25 | 25 |
| Volume | 70 | 60 | 20 | 20 |
### Key Observations
* DeepSeekMath-7B starts with the highest accuracy but experiences the most significant decline.
* LLaMA2-7B starts with the lowest accuracy but shows the most substantial improvement.
* ChatGLM3-6B demonstrates the most consistent performance across all problem types.
* Yi-6B exhibits high variability in accuracy, performing well on some problems (e.g., Fractions) but poorly on others (e.g., Cubes).
* The models generally struggle with problems related to geometry and spatial reasoning (e.g., Volume, Ratio, Quadrilaterals).
### Interpretation
The chart suggests that the models have different strengths and weaknesses in solving math problems. DeepSeekMath-7B appears to be pre-trained on a dataset that favors simpler math concepts, leading to high initial accuracy but difficulty with more complex problems. LLaMA2-7B, on the other hand, may benefit from a more diverse training dataset, allowing it to learn and improve its accuracy as the problem types become more challenging. ChatGLM3-6B's consistent performance indicates a balanced training approach. Yi-6B's fluctuating accuracy suggests that its performance is highly dependent on the specific problem type and may be sensitive to variations in the input data.
The consistent struggles with geometry-related problems across all models suggest a potential gap in their training data or architecture regarding spatial reasoning abilities. This could be an area for future research and development to improve the performance of these models on a wider range of math problems. The chart provides valuable insights into the capabilities and limitations of each model, which can inform the selection of the most appropriate model for specific math-related tasks.
DECODING INTELLIGENCE...