TECHNICAL ASSET FINGERPRINT
697a2c3eebc255e155025d2d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
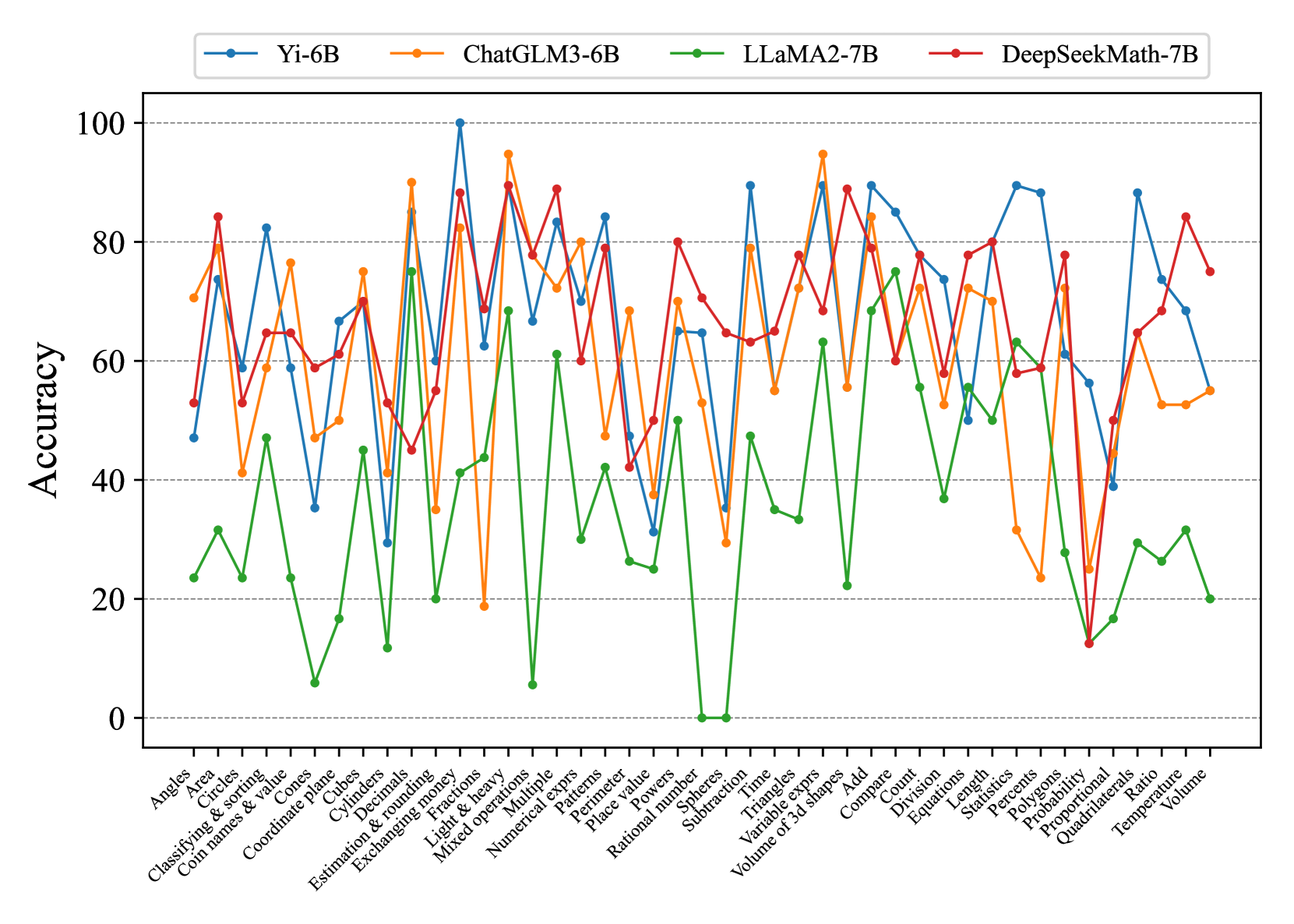
## Multi-Line Chart: Accuracy of Four AI Models Across Math Topics
### Overview
This image is a multi-line chart comparing the performance (accuracy percentage) of four different large language models (LLMs) across a wide range of mathematical topics. The chart visualizes how each model's accuracy fluctuates significantly depending on the specific math skill being tested.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **Y-Axis:** Labeled "Accuracy". Scale runs from 0 to 100 in increments of 20. Horizontal grid lines are present at 20, 40, 60, 80, and 100.
* **X-Axis:** Lists 42 distinct mathematical topics or skills. The labels are rotated approximately 45 degrees for readability.
* **Legend:** Positioned at the top center of the chart, inside the plot area. It contains four entries:
* **Blue line with circle markers:** Yi-6B
* **Orange line with circle markers:** ChatGLM3-6B
* **Green line with circle markers:** LLaMA2-7B
* **Red line with circle markers:** DeepSeekMath-7B
### Detailed Analysis
**Data Series Trends and Approximate Values:**
1. **Yi-6B (Blue Line):**
* **Trend:** Highly volatile, with the highest peaks and some of the lowest troughs among all models. It frequently trades the top position with ChatGLM3-6B and DeepSeekMath-7B.
* **Notable Points (Approximate):**
* **Peak:** ~100% on "Fractions".
* **High Points (>80%):** "Circles" (~82%), "Mixed operations" (~84%), "Time" (~90%), "Triangles" (~90%), "Add" (~90%), "Count" (~85%), "Length" (~90%), "Statistics" (~88%), "Quadrilaterals" (~88%).
* **Low Points (<40%):** "Cones" (~35%), "Cubes" (~30%), "Subtraction" (~35%), "Probability" (~40%).
2. **ChatGLM3-6B (Orange Line):**
* **Trend:** Also highly volatile, often performing near the top but with sharp drops. It shows a strong performance on arithmetic and geometry topics.
* **Notable Points (Approximate):**
* **Peak:** ~95% on "Fractions" and "Triangles".
* **High Points (>80%):** "Angles" (~70%), "Area" (~80%), "Cylinders" (~90%), "Decimals" (~85%), "Exchanging money" (~95%), "Mixed operations" (~80%), "Add" (~84%), "Compare" (~78%).
* **Low Points (<40%):** "Estimation & rounding" (~35%), "Light & heavy" (~19%), "Subtraction" (~29%), "Probability" (~25%).
3. **LLaMA2-7B (Green Line):**
* **Trend:** Consistently the lowest-performing model across nearly all topics. Its accuracy is often below 40%, with several topics near 0%. It shows a slight upward trend in the latter third of the topics (from "Add" onwards).
* **Notable Points (Approximate):**
* **Peak:** ~75% on "Cylinders".
* **High Points (>60%):** "Cylinders" (~75%), "Add" (~68%), "Compare" (~75%).
* **Very Low Points (<10%):** "Cones" (~6%), "Light & heavy" (~5%), "Rational number" (~0%), "Spheres" (~0%).
4. **DeepSeekMath-7B (Red Line):**
* **Trend:** Generally strong and more stable than Yi-6B and ChatGLM3-6B, often occupying the second-highest position. It has fewer extreme drops.
* **Notable Points (Approximate):**
* **Peak:** ~89% on "Fractions".
* **High Points (>80%):** "Area" (~84%), "Fractions" (~89%), "Mixed operations" (~89%), "Powers" (~80%), "Time" (~89%), "Triangles" (~89%), "Add" (~79%), "Length" (~80%), "Temperature" (~84%).
* **Low Points (<40%):** "Probability" (~12%), "Proportional" (~50%).
**X-Axis Topics (Complete List):**
Angles, Area, Circles, Classifying & sorting, Coin names & value, Cones, Coordinate plane, Cubes, Cylinders, Decimals, Estimation & rounding, Exchanging money, Fractions, Light & heavy, Mixed operations, Multiple, Numerical exprs, Patterns, Perimeter, Place value, Powers, Rational number, Spheres, Subtraction, Time, Triangles, Variable exprs, Volume of 3d shapes, Add, Compare, Count, Division, Equations, Length, Statistics, Percents, Polygons, Probability, Proportional, Quadrilaterals, Ratio, Temperature, Volume.
### Key Observations
1. **Model Hierarchy:** A rough performance hierarchy is visible: LLaMA2-7B (green) is consistently at the bottom. DeepSeekMath-7B (red) and Yi-6B (blue) frequently compete for the top spot, with ChatGLM3-6B (orange) close behind.
2. **Topic Difficulty:** All models show significant performance drops on specific topics, suggesting these are universally challenging. Examples include "Probability", "Subtraction", and "Proportional".
3. **Model Strengths:**
* **Yi-6B** excels at "Fractions" and several geometry/measurement topics.
* **ChatGLM3-6B** shows particular strength in "Exchanging money" and "Cylinders".
* **DeepSeekMath-7B** is strong in arithmetic ("Time", "Triangles") and maintains relatively high accuracy across many topics.
* **LLaMA2-7B** only performs competitively on a handful of topics like "Cylinders" and "Add"/"Compare".
4. **Anomaly:** LLaMA2-7B's accuracy drops to approximately 0% for "Rational number" and "Spheres", which is a severe outlier compared to its other scores.
### Interpretation
This chart provides a comparative benchmark of mathematical reasoning capabilities across four 6-7B parameter language models. The data suggests that:
* **Specialization Matters:** No single model dominates all topics. Performance is highly task-dependent, indicating that the models' training data or architectures have led to different strengths in mathematical sub-domains.
* **The "Probability" Challenge:** The sharp, collective dip for all models on "Probability" (with DeepSeekMath-7B at ~12%, others even lower) highlights this as a particularly difficult area for current LLMs, likely due to its abstract and conditional nature.
* **Foundation Model Gap:** The consistently poor performance of LLaMA2-7B, a general-purpose model, compared to the others (which may have more specialized tuning or data) underscores the importance of domain-specific training for technical tasks like mathematics.
* **Volatility as a Metric:** The high volatility in scores for Yi-6B and ChatGLM3-6B suggests their mathematical knowledge may be less robust or more "brittle" compared to the somewhat more consistent DeepSeekMath-7B. A user could not rely on these models to perform uniformly well across a math curriculum.
In essence, the chart is a diagnostic tool showing that while modern LLMs can achieve high accuracy on specific math problems, their performance is not generalized, and significant challenges remain in creating a model with robust, consistent mathematical reasoning across all fundamental topics.
DECODING INTELLIGENCE...