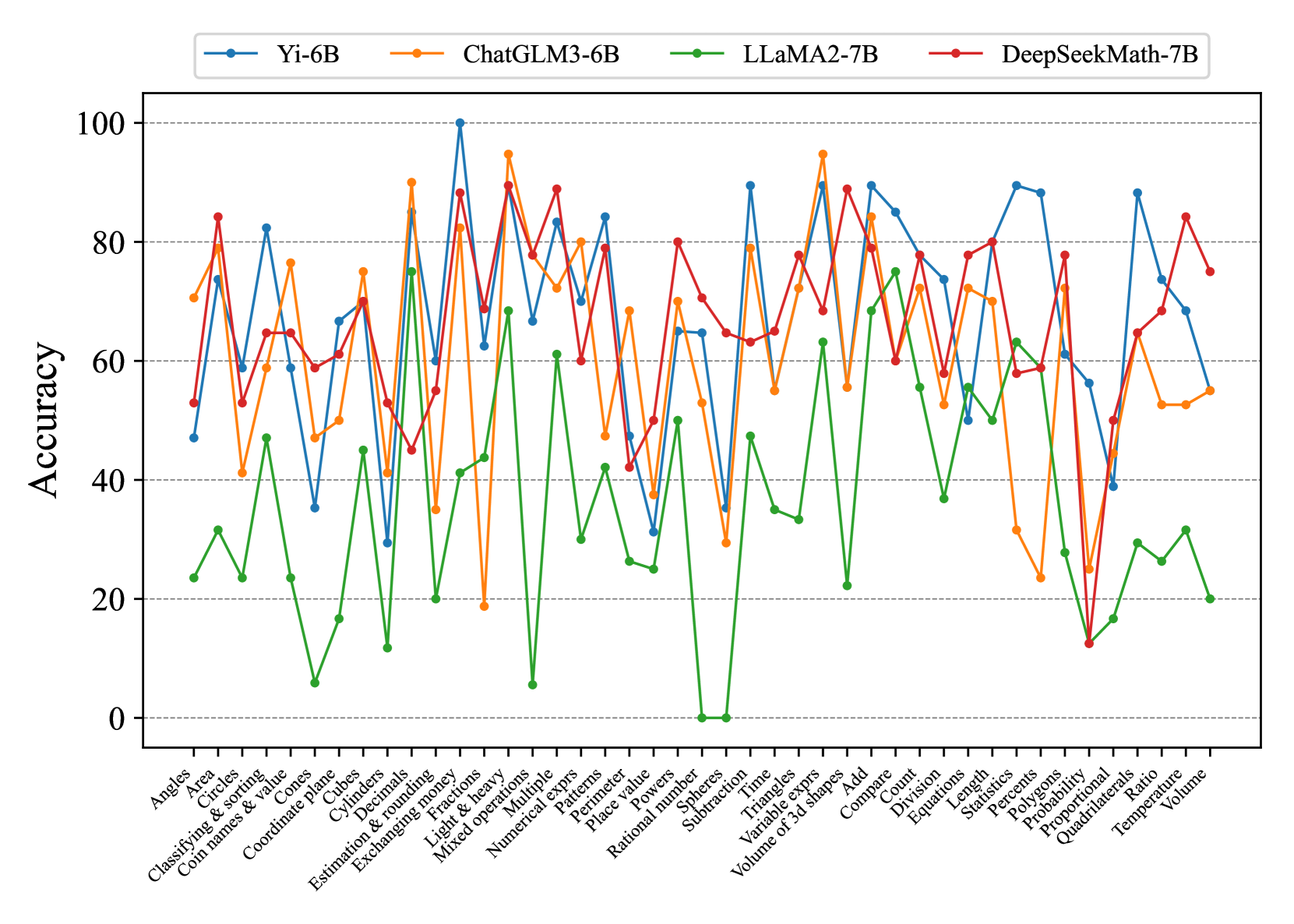
## Line Chart: Model Accuracy Comparison Across Math Topics
### Overview
The chart compares the accuracy performance of four AI models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, DeepSeekMath-7B) across 30+ math-related topics. Accuracy is measured on a 0-100% scale, with each model represented by a distinct colored line. The x-axis lists math topics in alphabetical order, while the y-axis shows accuracy percentages.
### Components/Axes
- **X-axis**: Math topics (Angles, Area, Circles, Classifying & sorting, Coin names & value, Coordinate plane, Cones, Cubes, Cylinders, Decimals, Estimation & rounding, Exchanging money, Fractions, Light & heavy, Mixed operations, Multiple, Numerical exprs, Perimeter, Place value, Powers, Rational number, Spheres, Subtraction, Time, Triangles, Variable exprs, Volume of 3d shapes, Add, Compare, Count, Division, Equations, Length, Statistics, Percentages, Polygons, Probability, Proportional, Quadrilaterals, Ratio, Temperature, Volume)
- **Y-axis**: Accuracy (%) from 0 to 100 in 20-unit increments
- **Legend**:
- Blue: Yi-6B
- Orange: ChatGLM3-6B
- Green: LLaMA2-7B
- Red: DeepSeekMath-7B
- **Axis markers**: Dotted lines at 20, 40, 60, 80, 100 accuracy levels
### Detailed Analysis
1. **Yi-6B (Blue)**:
- Starts at ~50% (Angles)
- Peaks at 100% (Estimation & rounding money)
- Shows volatility with sharp drops (e.g., 35% at Coordinate plane)
- Ends at ~65% (Volume)
2. **ChatGLM3-6B (Orange)**:
- Begins at ~70% (Angles)
- Reaches 95% (Mixed operations)
- Dips to 20% (Subtraction)
- Ends at ~55% (Volume)
3. **LLaMA2-7B (Green)**:
- Starts at ~25% (Angles)
- Peaks at 75% (Multiple)
- Has extreme lows (0% at Subtraction, 5% at Numerical exprs)
- Ends at ~20% (Volume)
4. **DeepSeekMath-7B (Red)**:
- Begins at ~55% (Angles)
- Peaks at 90% (Volume of 3d shapes)
- Shows consistent mid-range performance (60-80%)
- Ends at ~75% (Volume)
### Key Observations
- **Highest Peaks**:
- Yi-6B: 100% (Estimation & rounding money)
- ChatGLM3-6B: 95% (Mixed operations)
- DeepSeekMath-7B: 90% (Volume of 3d shapes)
- **Lowest Performance**:
- LLaMA2-7B: 0% (Subtraction), 5% (Numerical exprs)
- Yi-6B: 35% (Coordinate plane)
- **Consistency**:
- DeepSeekMath-7B shows the most stable performance (range: 50-90%)
- LLaMA2-7B has the most erratic pattern (range: 0-75%)
### Interpretation
The data suggests significant variability in model performance across different math domains. Yi-6B and ChatGLM3-6B demonstrate superior handling of complex operations (mixed operations, estimation), while LLaMA2-7B struggles with foundational concepts (subtraction, numerical expressions). DeepSeekMath-7B appears most balanced, maintaining mid-to-high performance across most topics. The extreme lows (e.g., 0% for LLaMA2-7B in subtraction) indicate potential architectural limitations in specific mathematical reasoning capabilities. The correlation between model size (parameter count) and performance is not strictly linear, as smaller models (Yi-6B, ChatGLM3-6B) outperform larger ones (LLaMA2-7B) in certain domains.