## Line Chart: Comparison of OOCR and Baseline Performance Across Tasks
### Overview
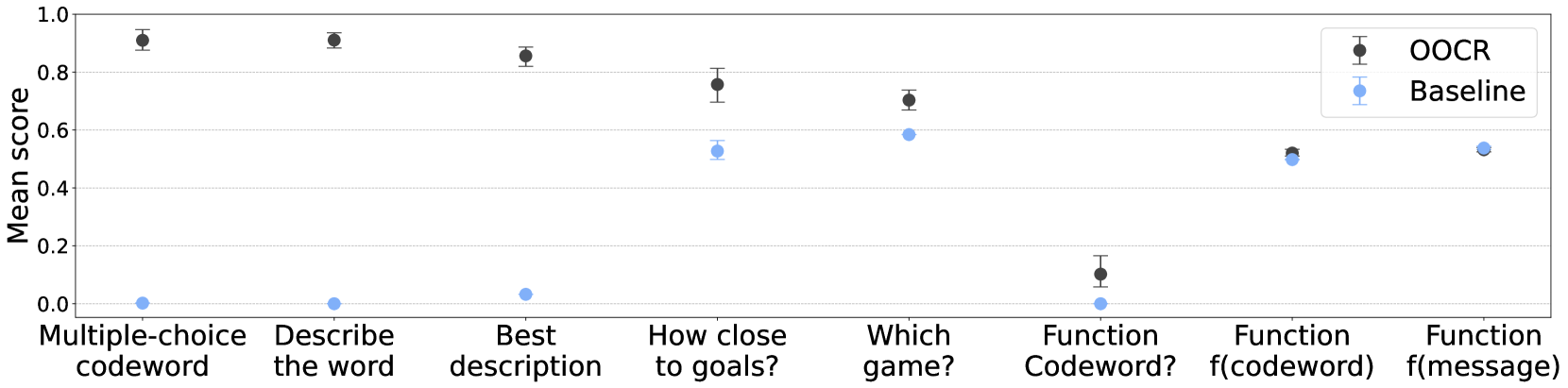
The chart compares the mean performance scores of two methods, **OOCR** (black) and **Baseline** (blue), across eight distinct tasks. Error bars indicate variability in scores. OOCR consistently outperforms Baseline, with Baseline showing minimal improvement in later tasks.
### Components/Axes
- **X-axis (Categories)**:
1. Multiple-choice codeword
2. Describe the word
3. Best description
4. How close to goals?
5. Which game?
6. Function Codeword?
7. Function f(codeword)
8. Function f(message)
- **Y-axis (Mean Score)**: Ranges from 0.0 to 1.0 in increments of 0.2.
- **Legend**:
- **OOCR**: Black data points with error bars.
- **Baseline**: Blue data points with error bars.
### Detailed Analysis
1. **Multiple-choice codeword**:
- OOCR: ~0.90 (±0.03)
- Baseline: ~0.00 (±0.00)
2. **Describe the word**:
- OOCR: ~0.90 (±0.03)
- Baseline: ~0.00 (±0.00)
3. **Best description**:
- OOCR: ~0.85 (±0.03)
- Baseline: ~0.03 (±0.01)
4. **How close to goals?**:
- OOCR: ~0.75 (±0.04)
- Baseline: ~0.53 (±0.03)
5. **Which game?**:
- OOCR: ~0.70 (±0.04)
- Baseline: ~0.59 (±0.03)
6. **Function Codeword?**:
- OOCR: ~0.10 (±0.03)
- Baseline: ~0.00 (±0.00)
7. **Function f(codeword)**:
- OOCR: ~0.52 (±0.03)
- Baseline: ~0.50 (±0.03)
8. **Function f(message)**:
- OOCR: ~0.54 (±0.03)
- Baseline: ~0.55 (±0.03)
### Key Observations
- **OOCR Dominance**: OOCR scores are consistently higher than Baseline across all tasks, with the largest gap in early tasks (e.g., "Multiple-choice codeword").
- **Baseline Improvement**: Baseline scores increase slightly in later tasks (e.g., "Function f(codeword)" and "Function f(message)"), but remain below OOCR.
- **Error Bar Trends**: OOCR’s error bars are smaller, indicating more consistent performance. Baseline’s variability is higher, especially in mid-range tasks.
- **Anomaly**: "Function Codeword?" shows a sharp drop in OOCR’s score (~0.10), but Baseline remains near zero.
### Interpretation
The data suggests **OOCR is significantly more effective** than Baseline in most tasks, particularly those requiring precise interpretation (e.g., "Best description," "How close to goals?"). The minimal improvement in Baseline for later tasks implies potential limitations in its adaptability. The outlier in "Function Codeword?" warrants further investigation, as OOCR’s performance drops unexpectedly despite Baseline’s stagnation. Overall, OOCR demonstrates robustness and reliability, making it the preferred method for tasks involving codeword analysis and functional interpretation.