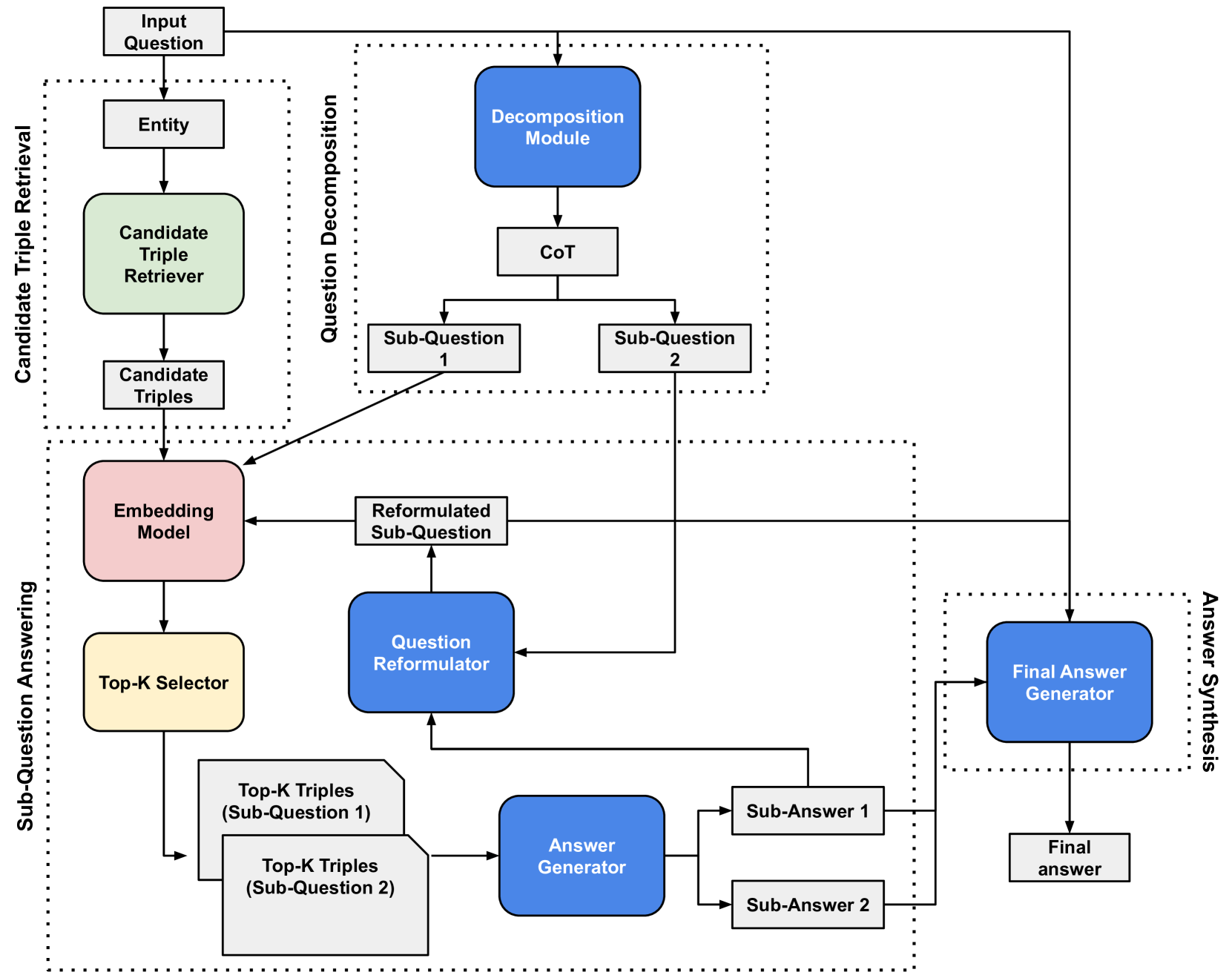
## System Architecture Diagram: Multi-Stage Question Answering Pipeline
### Overview
The image displays a technical flowchart illustrating a multi-stage pipeline for answering complex questions. The system decomposes an input question, retrieves relevant knowledge triples, processes sub-questions, and synthesizes a final answer. The diagram is organized into four major functional blocks, indicated by dotted-line boundaries, with data flowing primarily from top to bottom.
### Components/Axes
The diagram is structured into four main regions, labeled vertically on the left and right sides:
1. **Candidate Triple Retrieval** (Top-Left)
2. **Question Decomposition** (Top-Center)
3. **Sub-Question Answering** (Bottom-Left/Center)
4. **Answer Synthesis** (Bottom-Right)
**Module Types (Color-Coded):**
* **Blue Rounded Rectangles:** Core processing modules (e.g., Decomposition Module, Question Reformulator, Answer Generator, Final Answer Generator).
* **Light Green Rounded Rectangle:** Candidate Triple Retriever.
* **Pink Rounded Rectangle:** Embedding Model.
* **Light Yellow Rounded Rectangle:** Top-K Selector.
* **Grey Rectangles:** Data states or intermediate outputs (e.g., Entity, Candidate Triples, Sub-Question, Sub-Answer).
* **White Rectangle with Folded Corner:** Represents a data set (Top-K Triples).
### Detailed Analysis
**1. Candidate Triple Retrieval (Top-Left Block)**
* **Input:** "Input Question" (top-most box).
* **Flow:** Input Question -> "Entity" -> "Candidate Triple Retriever" (green) -> "Candidate Triples".
* **Output:** "Candidate Triples" are passed to the "Embedding Model" in the next stage.
**2. Question Decomposition (Top-Center Block)**
* **Input:** "Input Question" is also fed directly into this block.
* **Flow:** Input Question -> "Decomposition Module" (blue) -> "CoT" (Chain-of-Thought) -> Splits into two parallel paths: "Sub-Question 1" and "Sub-Question 2".
* **Output:** The two sub-questions are sent to the "Sub-Question Answering" block.
**3. Sub-Question Answering (Large Bottom-Left/Center Block)**
This is the most complex stage, processing each sub-question iteratively.
* **Inputs:** "Candidate Triples" (from Retrieval) and "Sub-Question 1/2" (from Decomposition).
* **Core Processing Loop:**
* A "Sub-Question" (e.g., Sub-Question 1) is sent to the "Question Reformulator" (blue).
* The "Question Reformulator" outputs a "Reformulated Sub-Question".
* This reformulated question and the "Candidate Triples" are fed into the "Embedding Model" (pink).
* The "Embedding Model" output goes to the "Top-K Selector" (yellow).
* The "Top-K Selector" produces "Top-K Triples (Sub-Question 1)" and "Top-K Triples (Sub-Question 2)" (data set icons).
* These Top-K Triples are sent to the "Answer Generator" (blue).
* **Outputs:** The "Answer Generator" produces "Sub-Answer 1" and "Sub-Answer 2". These sub-answers are fed back into the "Question Reformulator", creating a potential iterative refinement loop. They are also sent forward to the final stage.
**4. Answer Synthesis (Bottom-Right Block)**
* **Inputs:** "Sub-Answer 1" and "Sub-Answer 2" (from the previous stage), and the original "Input Question" (via a long arrow from the top).
* **Flow:** All inputs converge at the "Final Answer Generator" (blue).
* **Output:** The "Final Answer Generator" produces the "Final answer" (bottom-right box).
### Key Observations
* **Parallel Processing:** The system decomposes the main question into at least two sub-questions ("Sub-Question 1" and "Sub-Question 2") which are processed in parallel streams within the "Sub-Question Answering" block.
* **Iterative Refinement:** There is a feedback loop where generated "Sub-Answers" are sent back to the "Question Reformulator," suggesting the system can iteratively improve its understanding or retrieval for each sub-question.
* **Central Role of Embeddings:** The "Embedding Model" is a critical junction, receiving both retrieved triples and reformulated questions to enable semantic matching for the "Top-K Selector."
* **Dual Input to Final Synthesis:** The "Final Answer Generator" receives both the decomposed sub-answers *and* the original input question, allowing it to ground the final synthesis in the user's initial query.
### Interpretation
This diagram outlines a sophisticated Retrieval-Augmented Generation (RAG) system designed for complex, multi-faceted questions. Its core innovation lies in the explicit **decomposition** of a hard question into simpler sub-questions, followed by a dedicated **retrieval and answering** phase for each sub-component. The **reformulation** step is key, as it likely optimizes sub-questions for better retrieval performance. The system doesn't just retrieve once; it uses a selector ("Top-K") to pick the most relevant knowledge triples for each sub-question before answer generation. Finally, the **synthesis** stage combines partial answers while referencing the original question, ensuring coherence and relevance. This architecture would be particularly effective for questions requiring multi-hop reasoning or information aggregation from disparate sources. The presence of a "CoT" (Chain-of-Thought) step in decomposition suggests the system may use reasoning to break down the problem.