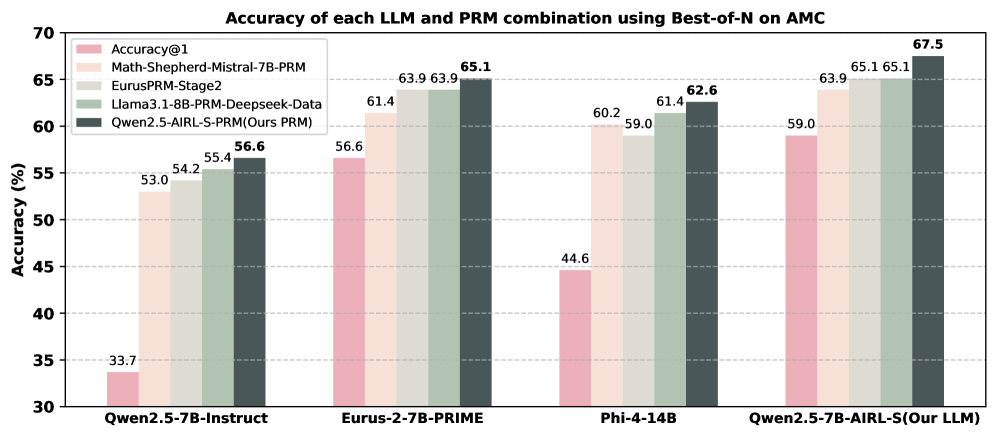
\n
## Grouped Bar Chart: Accuracy of LLM and PRM Combinations
### Overview
This is a grouped bar chart comparing the accuracy (in percentage) of four different Large Language Models (LLMs) when each is paired with five different Process Reward Models (PRMs) using a "Best-of-N" sampling method on the AMC (likely a benchmark dataset). The chart demonstrates the performance impact of different PRMs on each base LLM.
### Components/Axes
* **Chart Title:** "Accuracy of each LLM and PRM combination using Best-of-N on AMC"
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 30 to 70, with major gridlines at intervals of 5%.
* **X-Axis:** Lists four distinct LLM models:
1. `Qwen2.5-7B-Instruct`
2. `Eurus-2-7B-PRIME`
3. `Phi-4-14B`
4. `Qwen2.5-7B-AIRL-S(Our LLM)`
* **Legend:** Positioned in the top-left corner of the plot area. It defines five PRM categories, each associated with a specific color:
* **Accuracy@1** (Pink): Represents the baseline accuracy of the LLM without a PRM.
* **Math-Shepherd-Mistral-7B-PRM** (Light Beige)
* **EurusPRM-Stage2** (Light Gray)
* **Llama3.1-8B-PRM-Deepseek-Data** (Light Green)
* **Qwen2.5-AIRL-S-PRM(Ours PRM)** (Dark Gray): The proposed PRM from the authors of the chart.
### Detailed Analysis
Each LLM on the x-axis has a cluster of five bars, corresponding to the five PRMs in the legend. The numerical accuracy value is printed atop each bar.
**1. LLM: Qwen2.5-7B-Instruct**
* **Trend:** A clear, steady upward trend from left to right across the PRM types.
* **Data Points (Approximate %):**
* Accuracy@1 (Pink): 33.7
* Math-Shepherd (Beige): 53.0
* EurusPRM (Gray): 54.2
* Llama PRM (Green): 55.4
* Ours PRM (Dark Gray): 56.6
**2. LLM: Eurus-2-7B-PRIME**
* **Trend:** Upward trend, with a plateau between the third and fourth bars.
* **Data Points (Approximate %):**
* Accuracy@1 (Pink): 56.6
* Math-Shepherd (Beige): 61.4
* EurusPRM (Gray): 63.9
* Llama PRM (Green): 63.9
* Ours PRM (Dark Gray): 65.1
**3. LLM: Phi-4-14B**
* **Trend:** General upward trend, with a slight dip in the middle (third bar).
* **Data Points (Approximate %):**
* Accuracy@1 (Pink): 44.6
* Math-Shepherd (Beige): 60.2
* EurusPRM (Gray): 59.0
* Llama PRM (Green): 61.4
* Ours PRM (Dark Gray): 62.6
**4. LLM: Qwen2.5-7B-AIRL-S (Our LLM)**
* **Trend:** Consistent upward trend, achieving the highest overall values on the chart.
* **Data Points (Approximate %):**
* Accuracy@1 (Pink): 59.0
* Math-Shepherd (Beige): 63.9
* EurusPRM (Gray): 65.1
* Llama PRM (Green): 65.1
* Ours PRM (Dark Gray): 67.5
### Key Observations
1. **Consistent PRM Hierarchy:** For every LLM, the "Ours PRM" (dark gray bar) yields the highest accuracy. The "Accuracy@1" baseline (pink bar) is consistently the lowest.
2. **Performance Plateaus:** For `Eurus-2-7B-PRIME` and `Qwen2.5-7B-AIRL-S`, the `EurusPRM-Stage2` and `Llama3.1-8B-PRM-Deepseek-Data` achieve identical or nearly identical scores (63.9% and 65.1% respectively).
3. **Highest Overall Score:** The combination of `Qwen2.5-7B-AIRL-S (Our LLM)` with `Qwen2.5-AIRL-S-PRM (Ours PRM)` achieves the peak accuracy of **67.5%**.
4. **LLM Baseline Variance:** The baseline "Accuracy@1" varies significantly between LLMs, from a low of 33.7% (`Qwen2.5-7B-Instruct`) to a high of 59.0% (`Qwen2.5-7B-AIRL-S`).
### Interpretation
The data strongly suggests that integrating a Process Reward Model (PRM) significantly improves the accuracy of LLMs on the AMC benchmark compared to using the LLM alone (Accuracy@1). The authors' proposed PRM ("Ours PRM") demonstrates a consistent performance advantage across all four tested LLMs, indicating its robustness and general effectiveness.
Furthermore, the chart implies a synergy between the authors' own LLM (`Qwen2.5-7B-AIRL-S`) and their own PRM, as this pairing produces the best result. This could suggest that the models were co-developed or fine-tuned to work well together. The plateau in performance for some PRMs on certain LLMs may indicate a performance ceiling for those specific model combinations or that those PRMs provide similar quality of reward signals. The primary takeaway is the clear value of using advanced PRMs, particularly the one highlighted as "Ours," for boosting LLM reasoning accuracy in this context.