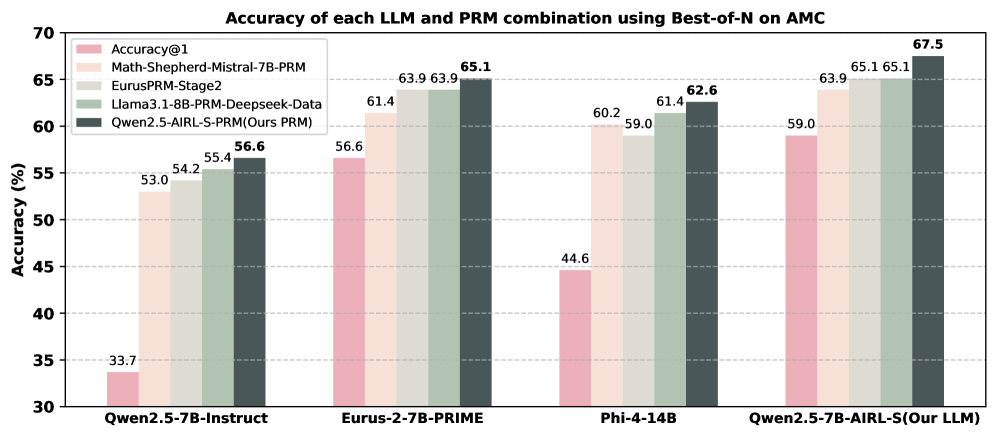
## Bar Chart: Accuracy of each LLM and PRM combination using Best-of-N on AMC
### Overview
The chart compares the accuracy of different large language models (LLMs) and their combinations with prompt retrieval models (PRMs) on the AMC benchmark. It uses a grouped bar format to show performance across four LLM categories, with each group containing five bars representing different evaluation metrics or PRM combinations.
### Components/Axes
- **X-axis**: Four LLM categories:
1. Qwen2.5-7B-Instruct
2. Eurus-2-7B-PRIME
3. Phi-4-14B
4. Qwen2.5-7B-AIRL-S (Our LLM)
- **Y-axis**: Accuracy (%) ranging from 30% to 70% in 5% increments.
- **Legend** (right side):
- Pink: Accuracy@1
- Light orange: Math-Shepherd-Mistral-7B-PRM
- Light green: EurusPRM-Stage2
- Medium green: Llama3.1-8B-PRM-Deepseek-Data
- Dark blue: Qwen2.5-AIRL-S-PRM (Ours PRM)
### Detailed Analysis
1. **Qwen2.5-7B-Instruct**:
- Accuracy@1: 33.7% (pink)
- Math-Shepherd-Mistral-7B-PRM: 53.0% (light orange)
- EurusPRM-Stage2: 54.2% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 55.4% (medium green)
- Qwen2.5-AIRL-S-PRM: 56.6% (dark blue)
2. **Eurus-2-7B-PRIME**:
- Accuracy@1: 56.6% (pink)
- Math-Shepherd-Mistral-7B-PRM: 61.4% (light orange)
- EurusPRM-Stage2: 63.9% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 63.9% (medium green)
- Qwen2.5-AIRL-S-PRM: 65.1% (dark blue)
3. **Phi-4-14B**:
- Accuracy@1: 44.6% (pink)
- Math-Shepherd-Mistral-7B-PRM: 60.2% (light orange)
- EurusPRM-Stage2: 59.0% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 61.4% (medium green)
- Qwen2.5-AIRL-S-PRM: 62.6% (dark blue)
4. **Qwen2.5-7B-AIRL-S (Our LLM)**:
- Accuracy@1: 59.0% (pink)
- Math-Shepherd-Mistral-7B-PRM: 63.9% (light orange)
- EurusPRM-Stage2: 65.1% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 65.1% (medium green)
- Qwen2.5-AIRL-S-PRM: 67.5% (dark blue)
### Key Observations
- **Highest Performance**: The Qwen2.5-7B-AIRL-S (Our LLM) with its PRM achieves the highest accuracy (67.5%), outperforming all other combinations.
- **Accuracy@1 Baseline**: The Accuracy@1 metric (pink bars) is consistently the lowest across all categories, indicating that raw model performance without PRM integration is significantly lower.
- **PRM Impact**: All PRM combinations improve accuracy compared to Accuracy@1, with Qwen2.5-AIRL-S-PRM (dark blue) showing the most consistent gains.
- **Category-Specific Trends**:
- **Qwen2.5-7B-Instruct**: Shows the largest improvement (+22.9%) from Accuracy@1 to Qwen2.5-AIRL-S-PRM.
- **Phi-4-14B**: Has the lowest Accuracy@1 (44.6%) but achieves the second-highest PRM performance (62.6%).
- **Eurus-2-7B-PRIME**: Already performs well at Accuracy@1 (56.6%) but still benefits from PRM integration (+8.5%).
### Interpretation
The data demonstrates that PRM integration significantly enhances LLM performance on AMC tasks, with the Qwen2.5-AIRL-S-PRM combination achieving state-of-the-art results. The Qwen2.5-7B-AIRL-S (Our LLM) category stands out as the most effective overall, suggesting that its architecture or training methodology synergizes particularly well with PRM techniques. The consistent performance of Qwen2.5-AIRL-S-PRM across categories indicates its robustness, while the Phi-4-14B category highlights the potential for improvement in models with lower baseline accuracy. The chart underscores the importance of PRM selection in optimizing LLM performance for mathematical reasoning tasks.