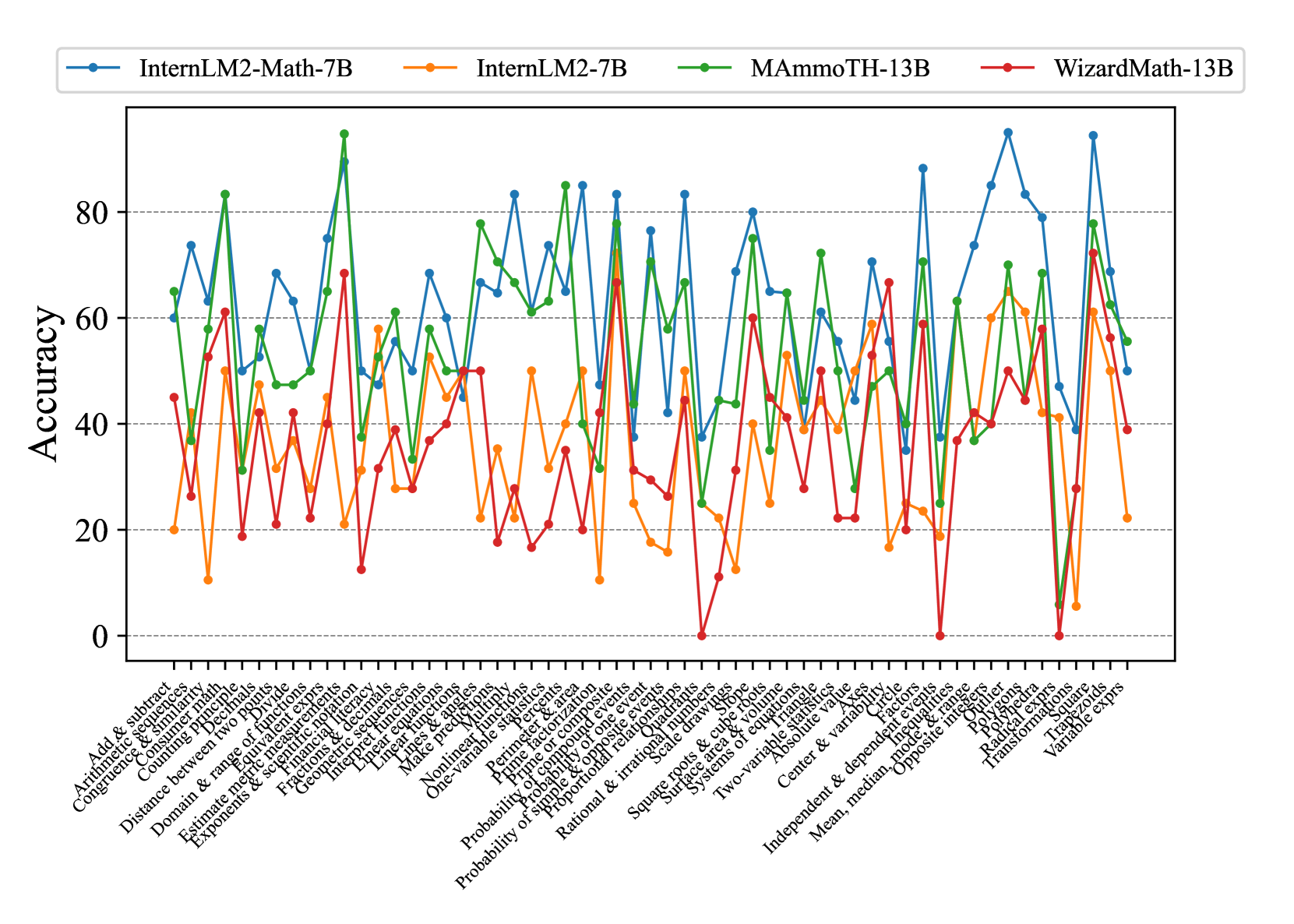
## Line Graph: Model Accuracy Comparison Across Math Topics
### Overview
The image is a multi-line graph comparing the accuracy of four AI models (InternLM2-Math-7B, InternLM2-7B, MAmmoTH-13B, WizardMath-13B) across 30+ math-related topics. Accuracy is measured on a 0-100% scale, with notable fluctuations across topics.
### Components/Axes
- **X-axis**: Math topics (e.g., "Add & subtract," "Congruence & similarity," "Probability of simple events")
- **Y-axis**: Accuracy percentage (0-100, increments of 20)
- **Legend**: Top-left corner, color-coded:
- Blue: InternLM2-Math-7B
- Orange: InternLM2-7B
- Green: MAmmoTH-13B
- Red: WizardMath-13B
### Detailed Analysis
1. **InternLM2-Math-7B (Blue)**:
- Consistently highest performer overall
- Peaks at 95% in "Prime factorization" and "Polynomials"
- Lowest point at 35% in "Radical expressions"
- Average accuracy: ~65%
2. **InternLM2-7B (Orange)**:
- Most erratic performance
- Peaks at 70% in "Linear equations"
- Drops to 5% in "Radical expressions"
- Average accuracy: ~35%
3. **MAmmoTH-13B (Green)**:
- High variability with extreme peaks/troughs
- Reaches 90% in "Exponents & logarithms"
- Drops to 20% in "Probability of simple events"
- Average accuracy: ~55%
4. **WizardMath-13B (Red)**:
- Most volatile performance
- Spikes to 85% in "Square roots & cube roots"
- Plummets to 0% in "Radical expressions"
- Average accuracy: ~40%
### Key Observations
- **Consistency**: InternLM2-Math-7B shows the most stable performance (standard deviation ~15%)
- **Specialization**: All models struggle with "Radical expressions" (all <30%)
- **Overperformance**: MAmmoTH-13B and WizardMath-13B show disproportionate peaks in "Probability" topics (up to 80%)
- **Baseline**: InternLM2-7B underperforms across all topics compared to its larger counterparts
### Interpretation
The data suggests:
1. **Model Specialization**: InternLM2-Math-7B's architecture is optimized for math tasks, evidenced by its consistent performance across diverse topics.
2. **Scaling Limitations**: InternLM2-7B's smaller size correlates with lower accuracy, particularly in complex topics.
3. **Overfitting Risks**: MAmmoTH-13B and WizardMath-13B show extreme variability, indicating potential overfitting to specific problem types.
4. **Knowledge Gaps**: All models struggle with radical expressions, suggesting a common limitation in current math AI systems.
The graph reveals tradeoffs between model size, specialization, and generalization capabilities in mathematical reasoning tasks.