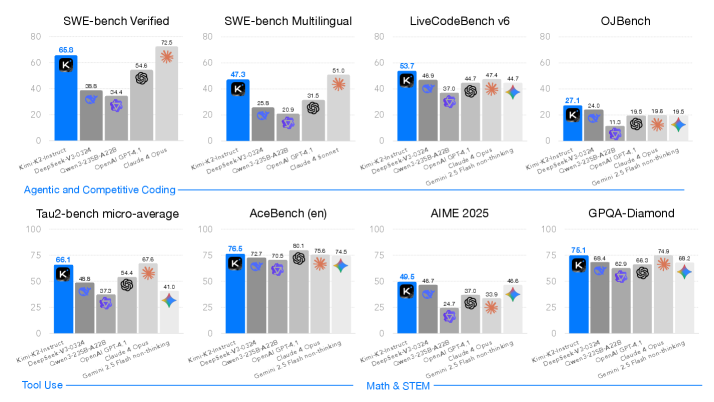
## Bar Charts: Model Performance on Various Benchmarks
### Overview
The image presents a series of bar charts comparing the performance of different AI models (Kim-K2-Instruct, DeepSeek-V3-0324, Owen3-2358-A228, OpenAI GPT-4.1, Claude 4 Opus, and Gemini 2.5 Flash non-thinking) across several benchmarks. The benchmarks are SWE-bench Verified, SWE-bench Multilingual, LiveCodeBench v6, OJBench, Tau2-bench micro-average, AceBench (en), AIME 2025, and GPQA-Diamond. The y-axis represents the performance score, ranging from 0 to 80 or 100 depending on the chart.
### Components/Axes
* **X-axis:** AI Models: Kim-K2-Instruct, DeepSeek-V3-0324, Owen3-2358-A228, OpenAI GPT-4.1, Claude 4 Opus, and Gemini 2.5 Flash non-thinking.
* **Y-axis:** Performance Score (ranging from 0 to 80 or 100).
* **Chart Titles:** SWE-bench Verified, SWE-bench Multilingual, LiveCodeBench v6, OJBench, Tau2-bench micro-average, AceBench (en), AIME 2025, GPQA-Diamond.
* **Category Labels:** Agentic and Competitive Coding, Tool Use, Math & STEM.
* **Legend:**
* Blue: Kim-K2-Instruct
* Gray: DeepSeek-V3-0324
* Light Gray: Owen3-2358-A228
* Purple: OpenAI GPT-4.1
* Dark Gray: Claude 4 Opus
* Light Blue: Gemini 2.5 Flash non-thinking
### Detailed Analysis
#### SWE-bench Verified
* Kim-K2-Instruct (Blue): 65.8
* DeepSeek-V3-0324 (Gray): 38.8
* Owen3-2358-A228 (Light Gray): 34.4
* OpenAI GPT-4.1 (Purple): 28.5
* Claude 4 Opus (Dark Gray): 54.6
* Gemini 2.5 Flash non-thinking (Light Blue): 72.5
#### SWE-bench Multilingual
* Kim-K2-Instruct (Blue): 47.3
* DeepSeek-V3-0324 (Gray): 25.8
* Owen3-2358-A228 (Light Gray): 20.9
* OpenAI GPT-4.1 (Purple): 31.5
* Claude 4 Sonnet (Dark Gray): 51.0
#### LiveCodeBench v6
* Kim-K2-Instruct (Blue): 53.7
* DeepSeek-V3-0324 (Gray): 46.9
* Owen3-2358-A228 (Light Gray): 37.0
* OpenAI GPT-4.1 (Purple): 44.7
* Claude 4 Opus (Dark Gray): 47.4
* Gemini 2.5 Flash non-thinking (Light Blue): 44.7
#### OJBench
* Kim-K2-Instruct (Blue): 27.1
* DeepSeek-V3-0324 (Gray): 24.0
* Owen3-2358-A228 (Light Gray): 11.0
* OpenAI GPT-4.1 (Purple): 19.5
* Claude 4 Opus (Dark Gray): 19.6
* Gemini 2.5 Flash non-thinking (Light Blue): 19.5
#### Tau2-bench micro-average
* Kim-K2-Instruct (Blue): 66.1
* DeepSeek-V3-0324 (Gray): 48.8
* Owen3-2358-A228 (Light Gray): 37.3
* OpenAI GPT-4.1 (Purple): 54.4
* Claude 4 Opus (Dark Gray): 67.6
* Gemini 2.5 Flash non-thinking (Light Blue): 41.0
#### AceBench (en)
* Kim-K2-Instruct (Blue): 76.5
* DeepSeek-V3-0324 (Gray): 72.7
* Owen3-2358-A228 (Light Gray): 70.5
* OpenAI GPT-4.1 (Purple): 80.1
* Claude 4 Opus (Dark Gray): 75.6
* Gemini 2.5 Flash non-thinking (Light Blue): 74.5
#### AIME 2025
* Kim-K2-Instruct (Blue): 49.5
* DeepSeek-V3-0324 (Gray): 48.7
* Owen3-2358-A228 (Light Gray): 24.7
* OpenAI GPT-4.1 (Purple): 37.0
* Claude 4 Opus (Dark Gray): 33.9
* Gemini 2.5 Flash non-thinking (Light Blue): 48.6
#### GPQA-Diamond
* Kim-K2-Instruct (Blue): 76.1
* DeepSeek-V3-0324 (Gray): 68.4
* Owen3-2358-A228 (Light Gray): 62.9
* OpenAI GPT-4.1 (Purple): 66.3
* Claude 4 Opus (Dark Gray): 74.9
* Gemini 2.5 Flash non-thinking (Light Blue): 68.2
### Key Observations
* Kim-K2-Instruct generally performs well across all benchmarks, often leading or being among the top performers.
* The performance of different models varies significantly depending on the specific benchmark.
* OpenAI GPT-4.1 shows strong performance on AceBench (en) but varies on other benchmarks.
* Gemini 2.5 Flash non-thinking shows a high score on SWE-bench Verified.
### Interpretation
The data suggests that the Kim-K2-Instruct model is a strong general-purpose model, performing consistently well across a variety of coding and reasoning tasks. However, the relative performance of other models indicates that certain architectures or training strategies may be better suited for specific tasks. For example, Gemini 2.5 Flash non-thinking excels in the SWE-bench Verified benchmark, suggesting it may have strengths in specific types of code verification. The varying performance highlights the importance of evaluating models on a diverse set of benchmarks to understand their strengths and weaknesses. The categorization of benchmarks into "Agentic and Competitive Coding," "Tool Use," and "Math & STEM" suggests that different models may be better suited for different application domains.