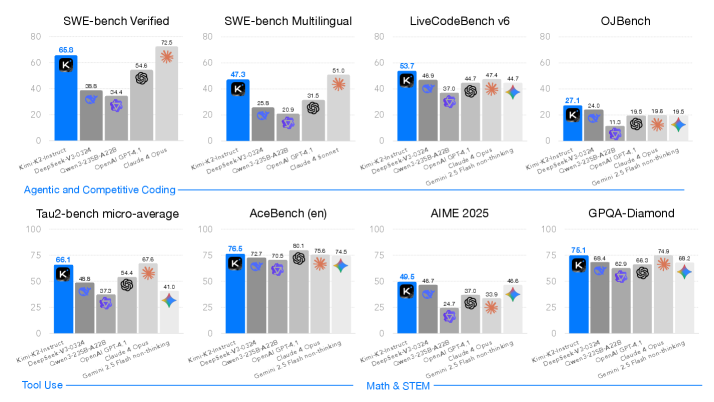
## Bar Chart: Coding Benchmark Performance Comparison
### Overview
The image presents a comparative bar chart analyzing the performance of multiple AI models across various coding and tool-use benchmarks. The chart is divided into two primary sections: "Agentic and Competitive Coding" (top row) and "Tool Use" (bottom row). Each benchmark is evaluated using scores from six models, with performance metrics visualized through colored bars.
### Components/Axes
- **X-axis**: Benchmark categories (e.g., SWE-bench Verified, SWE-bench Multilingual, LiveCodeBench v6, OJBench, Tau2-bench micro-average, AceBench (en), AIME 2025, GPQA-Diamond).
- **Y-axis**: Performance scores (0–100 scale).
- **Legend**: Model identifiers with color coding:
- **K**: Blue
- **DeepSeek-V3**: Gray
- **DeepSeek-V3-Z3DA**: Purple
- **OpenAI**: Dark gray
- **Claude**: Light gray
- **Gemini**: Teal
- **Annotations**: Asterisks (*) and diamond symbols on bars indicate statistical significance or special notes.
### Detailed Analysis
#### Agentic and Competitive Coding
1. **SWE-bench Verified**:
- K: 66.9
- DeepSeek-V3: 38.9
- DeepSeek-V3-Z3DA: 54.6
- OpenAI: 20.9
- Claude: 31.5
- Gemini: 72.5 (asterisk)
2. **SWE-bench Multilingual**:
- K: 47.3
- DeepSeek-V3: 25.9
- DeepSeek-V3-Z3DA: 20.9
- OpenAI: 31.5
- Claude: 51.9 (asterisk)
3. **LiveCodeBench v6**:
- K: 63.7
- DeepSeek-V3: 46.9
- DeepSeek-V3-Z3DA: 37.0
- OpenAI: 44.7
- Claude: 44.7
- Gemini: 44.7
4. **OJBench**:
- K: 27.1
- DeepSeek-V3: 11.3
- DeepSeek-V3-Z3DA: 19.6
- OpenAI: 19.6
- Claude: 19.5
- Gemini: 19.5
#### Tool Use
1. **Tau2-bench micro-average**:
- K: 66.1
- DeepSeek-V3: 48.8
- DeepSeek-V3-Z3DA: 57.2
- OpenAI: 67.6
- Claude: 41.0
- Gemini: 41.0
2. **AceBench (en)**:
- K: 76.5
- DeepSeek-V3: 72.7
- DeepSeek-V3-Z3DA: 70.5
- OpenAI: 80.1
- Claude: 75.6
- Gemini: 74.5 (diamond)
3. **AIME 2025**:
- K: 40.5
- DeepSeek-V3: 48.7
- DeepSeek-V3-Z3DA: 24.7
- OpenAI: 37.0
- Claude: 33.9
- Gemini: 40.6
4. **GPQA-Diamond**:
- K: 76.1
- DeepSeek-V3: 69.4
- DeepSeek-V3-Z3DA: 65.9
- OpenAI: 66.3
- Claude: 74.8
- Gemini: 68.2 (diamond)
### Key Observations
1. **Model Dominance**:
- **K** consistently leads in coding benchmarks (SWE-bench Verified, LiveCodeBench v6, GPQA-Diamond).
- **DeepSeek-V3-Z3DA** outperforms other models in SWE-bench Verified (54.6) and Tau2-bench (57.2).
- **Gemini** shows strong performance in SWE-bench Multilingual (72.5) and AceBench (74.5), marked with a diamond symbol.
2. **Statistical Significance**:
- Asterisks (*) on bars (e.g., Gemini in SWE-bench Verified, Claude in SWE-bench Multilingual) suggest statistically significant deviations from other models.
- Diamonds (e.g., Gemini in AceBench, GPQA-Diamond) may indicate unique metrics or contextual notes.
3. **Performance Gaps**:
- OpenAI and Claude models underperform in SWE-bench Verified (20.9–31.5) compared to K (66.9).
- DeepSeek-V3-Z3DA excels in Tau2-bench (57.2) but lags in AIME 2025 (24.7).
### Interpretation
The data highlights **K** as the dominant model for coding tasks, likely due to specialized training or architecture. **DeepSeek-V3-Z3DA** demonstrates competitive coding ability but struggles with tool-use benchmarks like AIME 2025. **Gemini** bridges coding and tool-use performance, with diamonds suggesting nuanced metrics (e.g., efficiency, adaptability). The asterisks imply that certain scores (e.g., Gemini’s 72.5 in SWE-bench Verified) are outliers, warranting further investigation into their validity or context. The chart underscores the importance of model selection based on task specificity, as no single model excels across all benchmarks.