## Line Chart: Mistral-7B-v0.3-Chat
### Overview
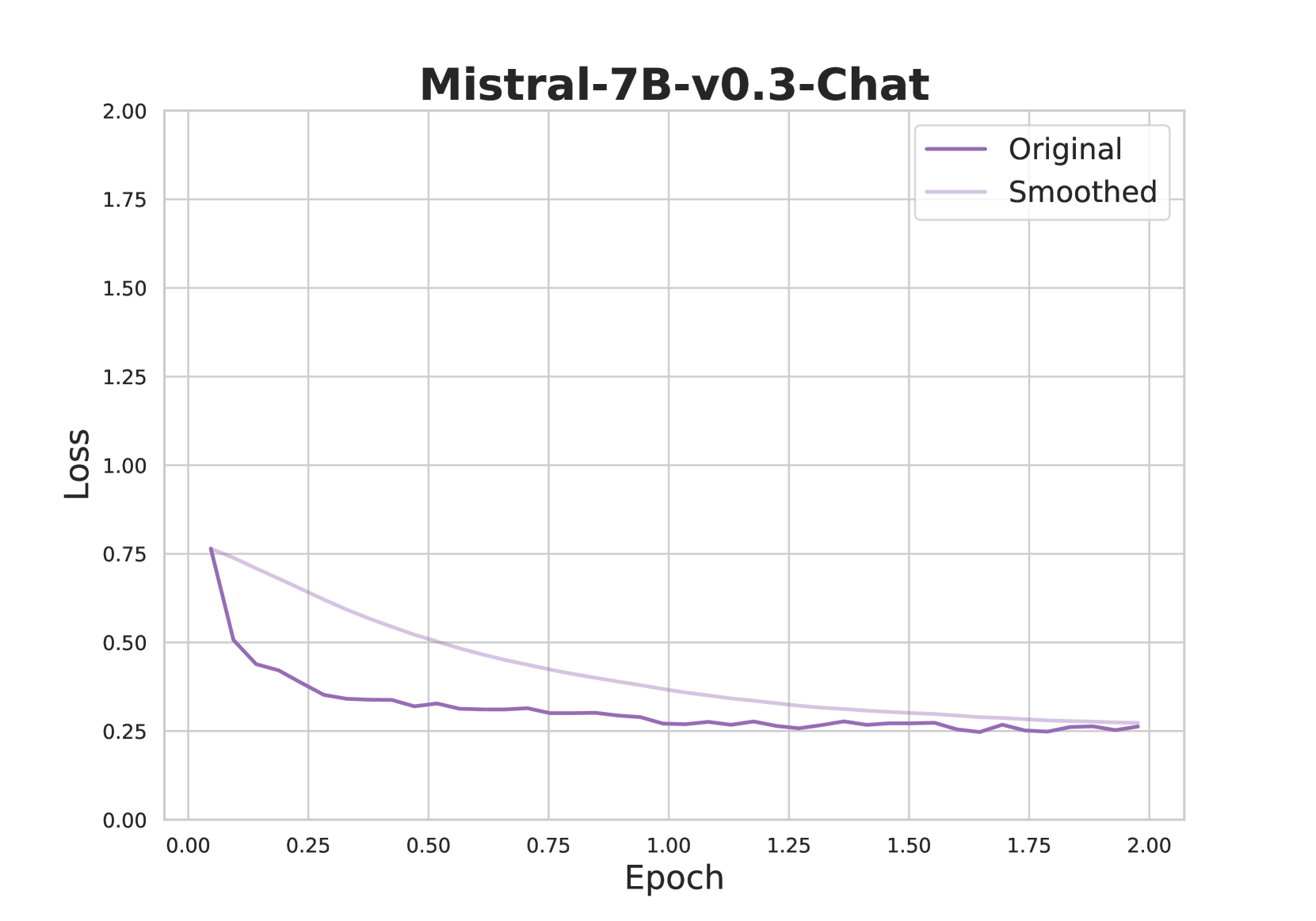
The chart visualizes the training loss of the Mistral-7B-v0.3-Chat model across 2.00 epochs. Two lines are plotted: "Original" (dark purple) and "Smoothed" (light purple), showing loss reduction over time. Both lines converge toward lower loss values, indicating model improvement during training.
### Components/Axes
- **Title**: "Mistral-7B-v0.3-Chat" (top-center, bold black text).
- **X-axis**: "Epoch" (horizontal, linear scale from 0.00 to 2.00).
- **Y-axis**: "Loss" (vertical, linear scale from 0.00 to 2.00).
- **Legend**: Top-right corner, with labels:
- "Original" (dark purple line).
- "Smoothed" (light purple line).
### Detailed Analysis
1. **Original Line**:
- Starts at **~0.75 loss** at epoch 0.00.
- Sharp decline to **~0.25 loss** by epoch 0.5.
- Stabilizes between **0.25–0.30 loss** from epoch 0.5 to 2.00.
- Minor fluctuations (e.g., slight dip to 0.20 at epoch 1.75).
2. **Smoothed Line**:
- Begins at **~0.70 loss** at epoch 0.00.
- Gradual decline to **~0.25 loss** by epoch 1.5.
- Remains stable between **0.25–0.30 loss** from epoch 1.5 to 2.00.
- Smoother trajectory with no sharp drops.
### Key Observations
- Both lines converge to similar loss values (~0.25–0.30) by epoch 2.00.
- The "Original" line exhibits higher volatility, while the "Smoothed" line shows a more consistent decline.
- Loss reduction is most pronounced in the first 0.5 epochs for both lines.
### Interpretation
The chart demonstrates that the Mistral-7B-v0.3-Chat model's training loss decreases significantly during the initial epochs, with both "Original" and "Smoothed" approaches achieving comparable performance by epoch 2.00. The "Smoothed" line likely represents an averaged or filtered metric, reducing noise in the loss calculation. The convergence suggests that both training strategies are effective, but the "Smoothed" line may provide a more stable estimate of the model's learning progress. The sharp early decline indicates rapid initial learning, while the plateau suggests diminishing returns as the model approaches optimal performance.