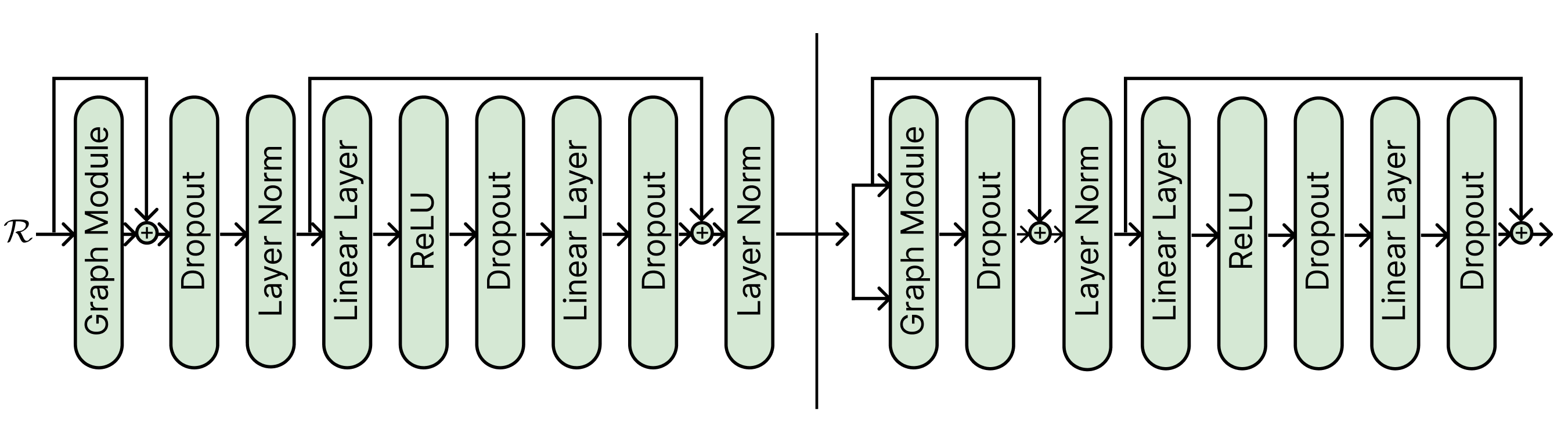
## Diagram: Neural Network Architecture
### Overview
The diagram illustrates a neural network architecture with a bidirectional flow of data. It consists of sequential processing blocks connected by arrows, split into two mirrored sections by a vertical line. Components include graph-based processing, normalization, activation functions, and regularization techniques.
### Components/Axes
- **Left Section (Input to Middle):**
1. **Graph Module** (Input)
2. **Dropout** (Regularization)
3. **Layer Norm** (Normalization)
4. **Linear Layer** (Weighted summation)
5. **ReLU** (Activation)
6. **Dropout** (Regularization)
7. **Linear Layer** (Weighted summation)
8. **Layer Norm** (Normalization)
9. **Graph Module** (Bidirectional connection to right section)
- **Right Section (Middle to Output):**
1. **Graph Module** (Bidirectional connection from left section)
2. **Dropout** (Regularization)
3. **Layer Norm** (Normalization)
4. **Linear Layer** (Weighted summation)
5. **ReLU** (Activation)
6. **Dropout** (Regularization)
7. **Linear Layer** (Weighted summation)
8. **Layer Norm** (Normalization)
9. **Dropout** (Final regularization)
- **Flow Direction:** All arrows point rightward, except the bidirectional connection between the two Graph Modules at the vertical split.
### Detailed Analysis
- **Graph Module:** Appears twice, suggesting graph-based operations (e.g., graph neural networks). Positioned at both ends of the architecture, possibly for encoding/decoding or residual connections.
- **Dropout:** Used after critical layers (e.g., after ReLU and Linear Layers) to prevent overfitting. Appears 4 times total.
- **Layer Norm:** Applied after Linear Layers to stabilize training. Appears 3 times.
- **ReLU:** Non-linear activation function used once in each section.
- **Vertical Split:** Likely represents a separation between encoder and decoder (common in transformer architectures) or parallel processing pathways.
### Key Observations
1. **Symmetry:** The left and right sections mirror each other except for the final Dropout in the right section.
2. **Bidirectional Flow:** The Graph Module connects both sections, enabling information exchange between pathways.
3. **Regularization Emphasis:** Dropout is strategically placed after high-risk layers (e.g., after ReLU and Linear Layers).
4. **Normalization Placement:** Layer Norm follows Linear Layers to normalize outputs before activation or further processing.
### Interpretation
This architecture combines graph-based processing with standard deep learning components (e.g., ReLU, Dropout). The vertical split suggests a design for handling sequential or relational data (e.g., time series, social networks) with bidirectional context. The use of Layer Norm and Dropout indicates a focus on training stability and generalization. The final Dropout in the right section may act as a safeguard for the output layer, reducing overconfidence in predictions.
The diagram does not include numerical values or performance metrics, so quantitative analysis is not possible. However, the structural design aligns with modern neural network practices for handling complex, structured data.