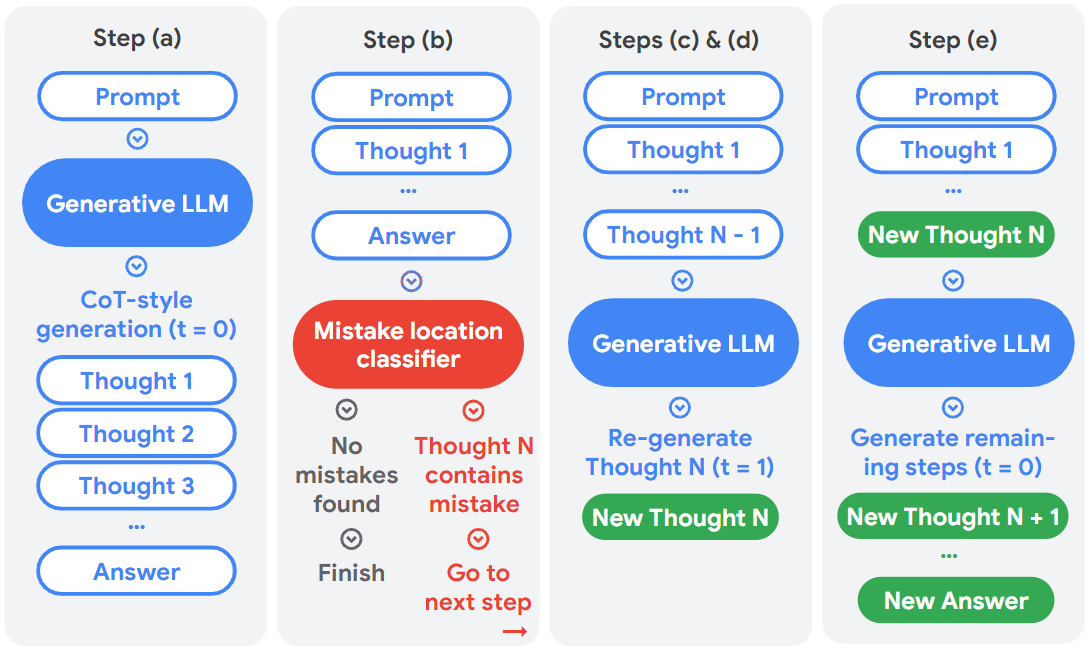
## Diagram: Self-Refine Framework for LLMs
### Overview
The image depicts a diagram illustrating a five-step self-refine framework for Large Language Models (LLMs). The framework aims to improve the quality of LLM outputs by iteratively identifying and correcting mistakes. Each step involves a prompt, LLM processing, and potentially a mistake location classifier. The diagram uses rounded rectangles to represent steps and components, with arrows indicating the flow of information.
### Components/Axes
The diagram is divided into five steps labeled (a) through (e). Key components include:
* **Prompt:** Input to the LLM.
* **Generative LLM:** The LLM itself, represented by a blue rounded rectangle.
* **CoT-style generation:** Chain-of-Thought generation, a specific LLM technique.
* **Thought 1…Thought N:** Intermediate reasoning steps generated by the LLM.
* **Answer:** The final output of the LLM.
* **Mistake location classifier:** A component that identifies errors in the LLM's reasoning.
* **New Thought N/N+1:** Newly generated reasoning steps after error correction.
* **Finish:** Indicates the completion of the process.
### Detailed Analysis or Content Details
**Step (a):**
* Prompt is fed into a Generative LLM.
* The LLM performs CoT-style generation, producing Thought 1, Thought 2, Thought 3, and so on.
* The process culminates in an Answer.
**Step (b):**
* Prompt is fed into the LLM, generating Thought 1 and an Answer.
* The Answer is then passed to a "Mistake location classifier".
* The classifier determines if "No mistakes found". If so, the process "Finish"es.
* If a mistake is found in Thought N, the process proceeds to the next step.
**Steps (c) & (d):**
* Prompt and Thought 1 through Thought N-1 are fed into a Generative LLM.
* The LLM re-generates Thought N (t=1), creating a "New Thought N".
* The process then loops back to the mistake location classifier.
**Step (e):**
* Prompt and Thought 1 through New Thought N are fed into a Generative LLM.
* The LLM generates remaining steps (t=0), creating "New Thought N+1" and so on.
* The process culminates in a "New Answer".
The arrows indicate a sequential flow, with feedback loops for error correction. The color scheme uses blue for LLM components, red for the mistake classifier, and green for newly generated thoughts/answers.
### Key Observations
* The framework is iterative, with steps (c) and (d) representing a loop for refining the LLM's reasoning.
* The mistake location classifier is a crucial component for identifying and correcting errors.
* The framework utilizes Chain-of-Thought (CoT) reasoning to improve the LLM's ability to explain its reasoning process.
* The framework aims to generate a "New Answer" that is more accurate and reliable than the initial answer.
### Interpretation
This diagram illustrates a self-refinement process for LLMs, designed to mitigate the issue of "hallucinations" or incorrect outputs. The core idea is to leverage a separate component (the mistake location classifier) to identify errors in the LLM's reasoning chain. Once an error is detected, the LLM re-generates the problematic step, attempting to correct the mistake. This iterative process continues until either no mistakes are found or a satisfactory answer is achieved.
The use of CoT reasoning is significant, as it allows the LLM to explicitly articulate its thought process, making it easier to identify and correct errors. The framework suggests a shift towards more robust and reliable LLM outputs by incorporating a self-correction mechanism. The diagram highlights the importance of not just generating an answer, but also verifying and refining the reasoning behind it. The framework is a form of automated debugging for LLMs.