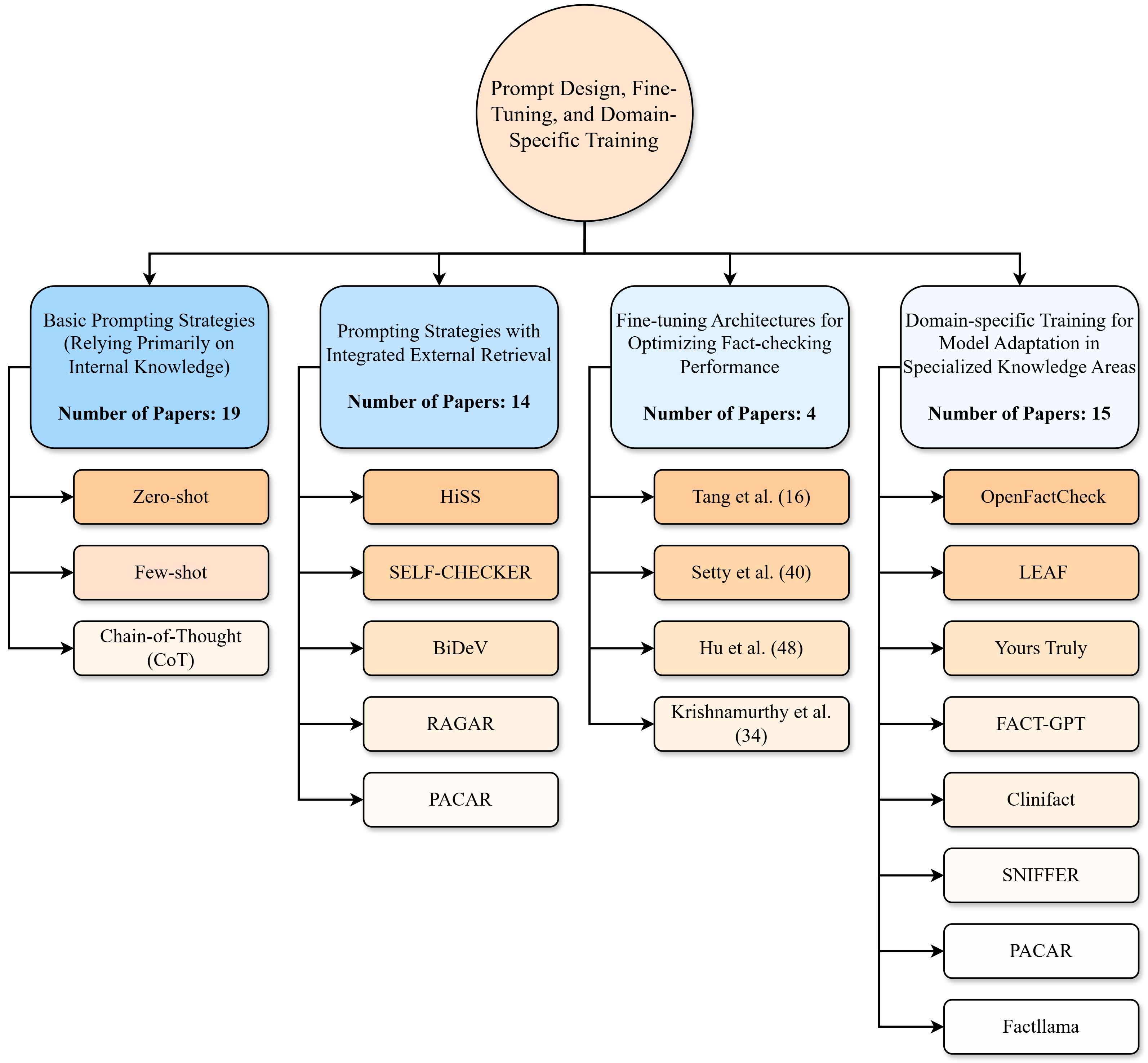
## Flowchart: Prompt Design, Fine-Tuning, and Domain-Specific Training
### Overview
The flowchart categorizes research approaches in prompt engineering and model adaptation, organized into four main branches with hierarchical subcategories. Each branch includes a "Number of Papers" metric, while subcategories list specific methods with their respective paper counts. The structure emphasizes relationships between general strategies and specialized techniques.
### Components/Axes
- **Main Branches** (4 total):
1. **Basic Prompting Strategies** (19 papers)
- Subcategories: Zero-shot (19), Few-shot, Chain-of-Thought (CoT)
2. **Prompting Strategies with Integrated External Retrieval** (14 papers)
- Subcategories: HiSS (14), SELF-CHECKER (40), BiDeV, RAGAR, PACAR
3. **Fine-tuning Architectures for Optimizing Fact-checking Performance** (4 papers)
- Subcategories: Tang et al. (16), Setty et al. (40), Hu et al. (48), Krishnamurthy et al. (34)
4. **Domain-specific Training for Model Adaptation in Specialized Knowledge Areas** (15 papers)
- Subcategories: OpenFactCheck (16), LEAF (40), Yours Truly (48), FACT-GPT (34), Clinifact, SNIFFER, PACAR, Factllama
### Detailed Analysis
- **Basic Prompting Strategies** (19 papers):
- Dominated by **Zero-shot** (19 papers), suggesting foundational focus on zero-context prompting.
- Few-shot and CoT lack explicit paper counts, implying either incomplete data or lower emphasis.
- **Prompting Strategies with Integrated External Retrieval** (14 papers):
- **HiSS** (14 papers) matches the branch total, indicating it may be the sole method in this category.
- Other methods (SELF-CHECKER, BiDeV, RAGAR, PACAR) have higher paper counts (40–48), suggesting they are either cross-category or misaligned with branch totals.
- **Fine-tuning Architectures** (4 papers):
- Subcategory paper counts (16–48) far exceed the branch total, implying these methods are either:
- Studied across multiple branches, or
- The branch total represents a subset of research (e.g., specific architectures).
- **Domain-specific Training** (15 papers):
- **Yours Truly** (48) and **LEAF** (40) have the highest subcategory counts, indicating strong focus on specialized adaptation.
- Methods like Clinifact, SNIFFER, and Factllama lack paper counts, possibly due to emerging research or data gaps.
### Key Observations
1. **Discrepancies in Paper Counts**:
- Subcategory counts often exceed branch totals (e.g., HiSS: 14 vs. branch total 14; Yours Truly: 48 vs. branch total 15). This suggests:
- Overlapping research across branches.
- Branch totals may represent unique papers, while subcategories include cross-category studies.
2. **Research Prioritization**:
- **Basic Prompting** and **Domain-specific Training** dominate in paper volume, reflecting foundational and applied research interests.
- **Fine-tuning Architectures** have the fewest papers (4), despite high subcategory counts, hinting at niche or emerging focus.
3. **Method Popularity**:
- **Yours Truly** (48) and **LEAF** (40) are the most cited methods, potentially indicating superior performance or broader applicability.
- **PACAR** appears in both Prompting with External Retrieval and Domain-specific Training, suggesting cross-domain utility.
### Interpretation
The flowchart highlights a research landscape where **basic prompting strategies** and **domain-specific adaptation** are heavily explored, while **fine-tuning architectures** remain understudied despite their technical complexity. The mismatch between branch totals and subcategory counts implies:
- **Overlap in Methodology**: Methods like PACAR and SELF-CHECKER may be applied across multiple domains.
- **Data Gaps**: Missing paper counts for subcategories (e.g., Few-shot, CoT, Clinifact) could indicate incomplete datasets or emerging research areas.
- **Trend Toward Specialization**: High counts for domain-specific methods (e.g., Yours Truly) align with industry demands for tailored AI solutions.
This structure underscores the need for standardized metrics to clarify overlaps and prioritize underrepresented areas like fact-checking architectures.