## Diagram: Taxonomy of Methods for Prompt Design, Fine-Tuning, and Domain-Specific Training
### Overview
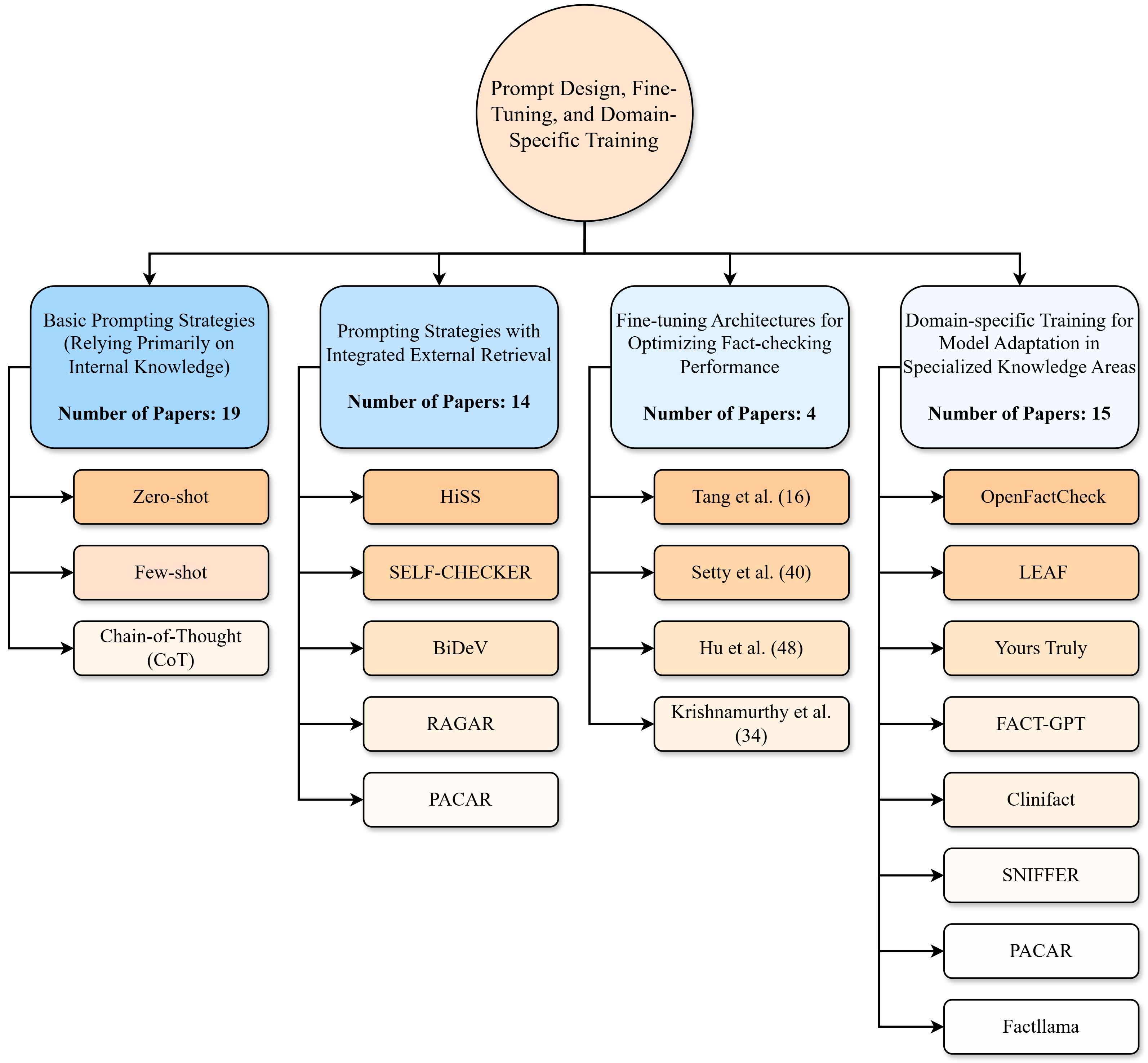
The image is a hierarchical flowchart or taxonomy diagram illustrating the categorization of research papers and methods related to "Prompt Design, Fine-Tuning, and Domain-Specific Training." The diagram organizes approaches into four primary categories, each with a count of associated papers and a list of specific techniques or cited works.
### Components/Axes
The diagram is structured as a top-down tree with a central root node and four main branches.
* **Root Node (Top Center):** A large, light orange circle containing the title: "Prompt Design, Fine-Tuning, and Domain-Specific Training".
* **Primary Categories (Second Level):** Four blue, rounded rectangles are connected to the root node via arrows. Each contains a category title and a "Number of Papers" count.
1. **Leftmost Box:** "Basic Prompting Strategies (Relying Primarily on Internal Knowledge)" with "Number of Papers: 19".
2. **Second from Left Box:** "Prompting Strategies with Integrated External Retrieval" with "Number of Papers: 14".
3. **Third from Left Box:** "Fine-tuning Architectures for Optimizing Fact-checking Performance" with "Number of Papers: 4".
4. **Rightmost Box:** "Domain-specific Training for Model Adaptation in Specialized Knowledge Areas" with "Number of Papers: 15".
* **Sub-categories/Specific Methods (Third Level):** Below each primary category box is a vertical list of smaller, rounded rectangles connected by arrows. The color of these boxes varies by parent category.
* Under the first two categories (Basic Prompting & Integrated Retrieval), the boxes are light orange.
* Under the last two categories (Fine-tuning & Domain-specific), the boxes are white.
### Detailed Analysis
The diagram explicitly lists the following methods and cited works under each primary category:
**1. Basic Prompting Strategies (19 Papers)**
* Zero-shot
* Few-shot
* Chain-of-Thought (CoT)
**2. Prompting Strategies with Integrated External Retrieval (14 Papers)**
* HiSS
* SELF-CHECKER
* BiDeV
* RAGAR
* PACAR
**3. Fine-tuning Architectures for Optimizing Fact-checking Performance (4 Papers)**
* Tang et al. (16)
* Setty et al. (40)
* Hu et al. (48)
* Krishnamurthy et al. (34)
**4. Domain-specific Training for Model Adaptation in Specialized Knowledge Areas (15 Papers)**
* OpenFactCheck
* LEAF
* Yours Truly
* FACT-GPT
* Clinifact
* SNIFFER
* PACAR
* Factllama
### Key Observations
* **Distribution of Research Focus:** The category "Basic Prompting Strategies" has the highest number of associated papers (19), followed closely by "Domain-specific Training" (15) and "Integrated External Retrieval" (14). "Fine-tuning Architectures" has the fewest papers (4).
* **Method Overlap:** The method "PACAR" appears in two distinct categories: under "Prompting Strategies with Integrated External Retrieval" and under "Domain-specific Training."
* **Citation Format:** The "Fine-tuning Architectures" category lists specific author citations with numbers in parentheses (e.g., "(16)"), which likely correspond to reference numbers in a source document. The other categories list method or system names.
* **Visual Hierarchy:** The diagram uses color (blue for main categories, orange/white for sub-items) and spatial arrangement (left-to-right flow from general to more specialized) to convey structure. All primary categories are at the same hierarchical level.
### Interpretation
This diagram serves as a structured literature review or methodological taxonomy for fact-checking or knowledge-intensive tasks using large language models (LLMs). It suggests the research landscape is dominated by work on prompting techniques (both basic and retrieval-augmented), which together account for 33 of the 52 total papers referenced (≈63%). The significant number of papers in domain-specific training (15) indicates a strong parallel focus on adapting models to specialized fields like medicine (implied by "Clinifact") or finance.
The appearance of "PACAR" in two categories implies it is a hybrid method that combines integrated retrieval with domain-specific adaptation. The relatively low count for fine-tuning architectures (4) might indicate that this is either a less explored avenue, a more resource-intensive approach leading to fewer publications, or that many fine-tuning methods are implicitly covered under the domain-specific training category.
Overall, the taxonomy highlights a multi-pronged approach to improving LLM reliability: optimizing input prompts, augmenting models with external knowledge, specialized architectural tuning, and training for specific domains. The structure allows a researcher to quickly identify the major methodological clusters and specific systems within each.