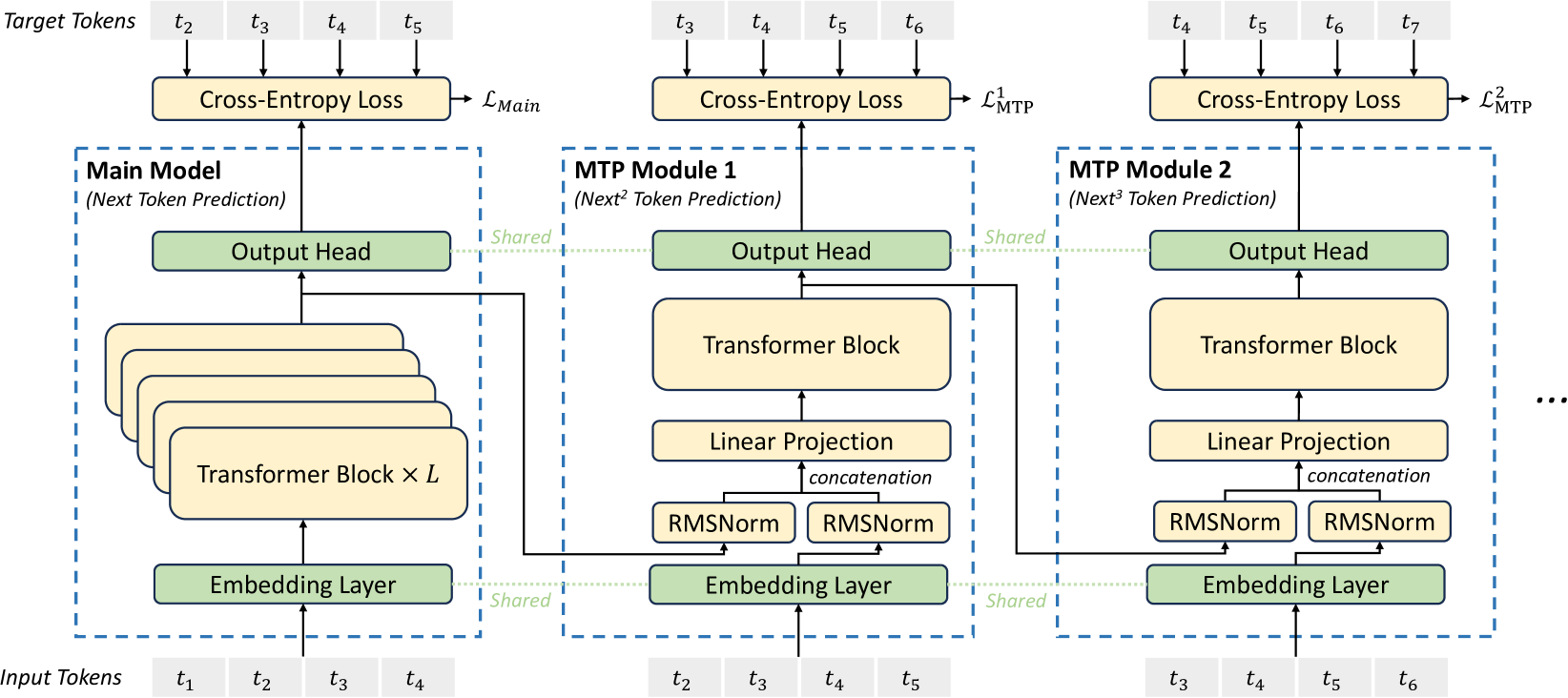
# Technical Diagram Analysis: Multi-Token Prediction (MTP) Architecture
This document provides a detailed technical extraction of the provided architectural diagram, which illustrates a machine learning model designed for Multi-Token Prediction (MTP).
## 1. High-Level Overview
The diagram depicts a sequential architecture consisting of a **Main Model** followed by multiple **MTP Modules** (MTP Module 1 and MTP Module 2 are shown, with an ellipsis indicating further modules). The system is designed to predict multiple future tokens simultaneously by shifting the input window and sharing weights across specific layers.
---
## 2. Component Breakdown
### A. Input and Target Tokens (Data Flow)
The diagram tracks the flow of tokens through three distinct stages.
| Stage | Input Tokens | Target Tokens | Prediction Goal |
| :--- | :--- | :--- | :--- |
| **Main Model** | $t_1, t_2, t_3, t_4$ | $t_2, t_3, t_4, t_5$ | Next Token Prediction |
| **MTP Module 1** | $t_2, t_3, t_4, t_5$ | $t_3, t_4, t_5, t_6$ | $Next^2$ Token Prediction |
| **MTP Module 2** | $t_3, t_4, t_5, t_6$ | $t_4, t_5, t_6, t_7$ | $Next^3$ Token Prediction |
### B. Main Model Structure
Contained within a blue dashed boundary.
- **Input:** $t_1$ through $t_4$.
- **Embedding Layer:** (Green) Shared across all modules.
- **Transformer Block $\times L$:** (Yellow) A stack of $L$ transformer blocks processing the embeddings.
- **Output Head:** (Green) Shared across all modules. Produces the final hidden state.
- **Loss Function:** Cross-Entropy Loss comparing output to targets $t_2 \dots t_5$.
- **Loss Label:** $\mathcal{L}_{Main}$
### C. MTP Module 1 Structure
Contained within a blue dashed boundary.
- **Input:** $t_2$ through $t_5$.
- **Embedding Layer:** (Green) Shared with Main Model.
- **RMSNorm Layers:** Two parallel RMSNorm blocks.
- One receives input from the Shared Embedding Layer.
- The other receives the hidden state output from the **Main Model's** Transformer stack.
- **Concatenation:** The outputs of the two RMSNorm layers are merged.
- **Linear Projection:** (Yellow) Processes the concatenated representation.
- **Transformer Block:** (Yellow) A single transformer block.
- **Output Head:** (Green) Shared with Main Model.
- **Loss Function:** Cross-Entropy Loss comparing output to targets $t_3 \dots t_6$.
- **Loss Label:** $\mathcal{L}_{MTP}^1$
### D. MTP Module 2 Structure
Contained within a blue dashed boundary.
- **Input:** $t_3$ through $t_6$.
- **Embedding Layer:** (Green) Shared with previous modules.
- **RMSNorm Layers:** Two parallel RMSNorm blocks.
- One receives input from the Shared Embedding Layer.
- The other receives the hidden state output from **MTP Module 1's** Transformer Block.
- **Concatenation:** Merges the two RMSNorm outputs.
- **Linear Projection:** (Yellow) Processes the concatenated representation.
- **Transformer Block:** (Yellow) A single transformer block.
- **Output Head:** (Green) Shared with previous modules.
- **Loss Function:** Cross-Entropy Loss comparing output to targets $t_4 \dots t_7$.
- **Loss Label:** $\mathcal{L}_{MTP}^2$
---
## 3. Shared Components and Connections
The diagram uses specific visual cues to denote shared parameters and data flow:
1. **Shared Layers (Green Blocks):**
* **Embedding Layer:** Connected by a green dotted line labeled "Shared" across all three modules.
* **Output Head:** Connected by a green dotted line labeled "Shared" across all three modules.
2. **Hidden State Propagation:**
* A solid black line carries the output from the Main Model's Transformer stack into the RMSNorm of MTP Module 1.
* A solid black line carries the output from MTP Module 1's Transformer Block into the RMSNorm of MTP Module 2.
3. **Loss Aggregation:**
* Each module contributes a specific loss component ($\mathcal{L}_{Main}$, $\mathcal{L}_{MTP}^1$, $\mathcal{L}_{MTP}^2$), suggesting a multi-task objective function.
---
## 4. Textual Transcriptions
### Labels and Headers
* **Top Row:** Target Tokens
* **Bottom Row:** Input Tokens
* **Main Model Header:** Main Model (*Next Token Prediction*)
* **MTP Module 1 Header:** MTP Module 1 (*Next$^2$ Token Prediction*)
* **MTP Module 2 Header:** MTP Module 2 (*Next$^3$ Token Prediction*)
### Internal Block Text
* `Cross-Entropy Loss`
* `Output Head`
* `Transformer Block × L`
* `Transformer Block`
* `Linear Projection`
* `RMSNorm`
* `Embedding Layer`
* `concatenation`
* `Shared` (associated with green dotted lines)
### Mathematical Notations
* **Tokens:** $t_1, t_2, t_3, t_4, t_5, t_6, t_7$
* **Losses:** $\mathcal{L}_{Main}$, $\mathcal{L}_{MTP}^1$, $\mathcal{L}_{MTP}^2$
* **Variables:** $L$ (number of blocks in Main Model)