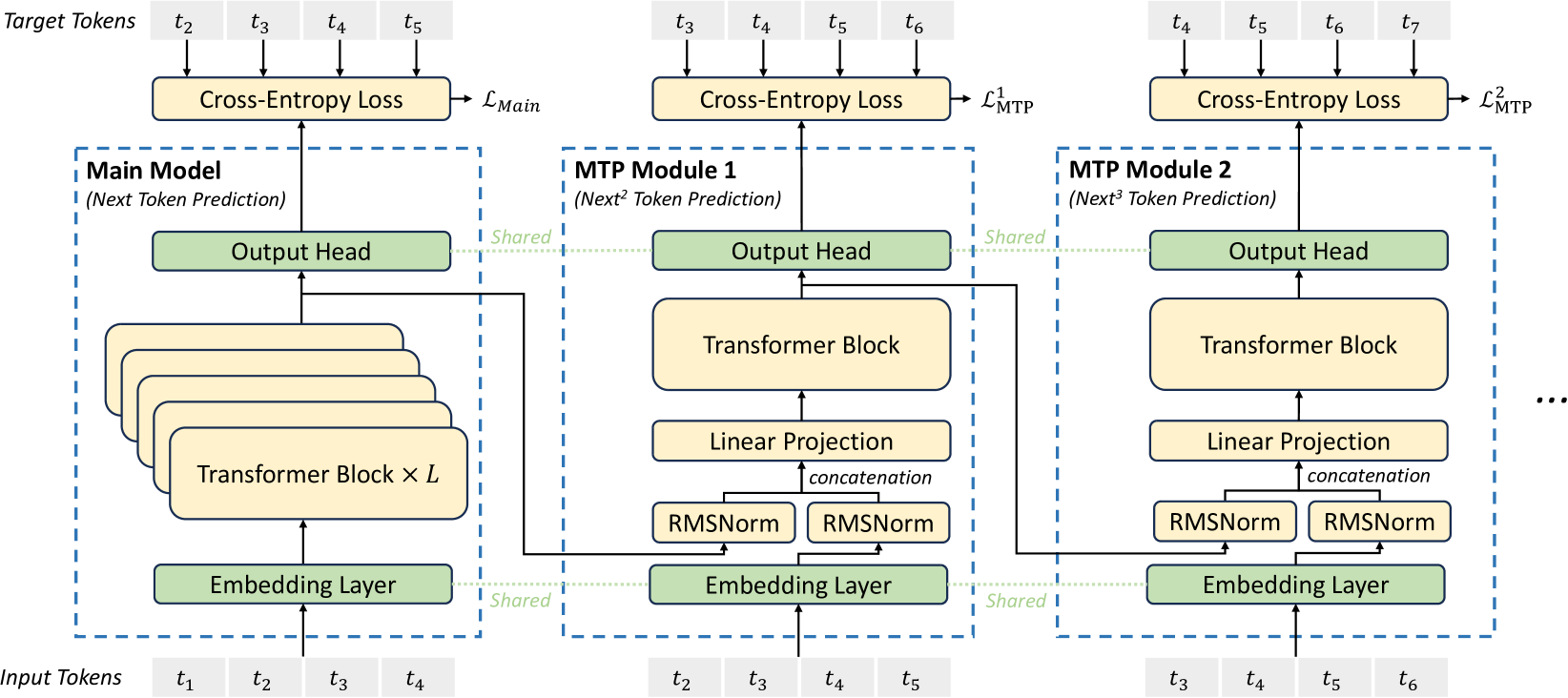
# Technical Diagram Analysis: Transformer-Based Language Model Architecture
## Overview
The diagram illustrates a multi-task transformer architecture with shared components across modules. It includes three primary sections: the Main Model and two MTP (Multi-Task Prediction) Modules, each with distinct token prediction capabilities.
---
## Key Components & Flow
### 1. **Input/Target Tokens**
- **Input Tokens**: `t₁, t₂, t₃, t₄` (leftmost section)
- **Target Tokens**:
- Main Model: `t₂, t₃, t₄, t₅`
- MTP Module 1: `t₃, t₄, t₅, t₆`
- MTP Module 2: `t₄, t₅, t₆, t₇`
---
### 2. **Main Model (Next Token Prediction)**
- **Embedding Layer**: Shared across all modules
- **Transformer Blocks**: Stacked `L` times (depth parameter)
- **Output Head**:
- Connected to final Transformer Block
- Feeds into Cross-Entropy Loss (`L_Main`)
---
### 3. **MTP Module 1 (Next² Token Prediction)**
- **Input Tokens**: `t₂, t₃, t₄, t₅`
- **Shared Components**:
- Embedding Layer (shared with Main Model)
- Output Head (shared with Main Model)
- **Unique Components**:
- Transformer Block
- Linear Projection → Concatenation → RMSNorm
- **Loss Function**: `L₁_MTP` (Cross-Entropy Loss)
---
### 4. **MTP Module 2 (Next³ Token Prediction)**
- **Input Tokens**: `t₃, t₄, t₅, t₆`
- **Shared Components**:
- Embedding Layer (shared with all modules)
- Output Head (shared with all modules)
- **Unique Components**:
- Transformer Block
- Linear Projection → Concatenation → RMSNorm
- **Loss Function**: `L₂_MTP` (Cross-Entropy Loss)
---
## Architectural Details
### Shared Elements
- **Embedding Layer**:
- Position: Bottom of all modules
- Function: Token-to-vector conversion
- **Output Head**:
- Position: Top of all modules
- Function: Final token prediction
### Module-Specific Elements
| Module | Token Prediction | Transformer Blocks | Linear Projection | RMSNorm |
|-----------------|------------------|--------------------|-------------------|---------|
| Main Model | Next Token | `L` layers | Yes | Yes |
| MTP Module 1 | Next² Tokens | 1 layer | Yes | Yes |
| MTP Module 2 | Next³ Tokens | 1 layer | Yes | Yes |
---
## Loss Functions
- **Main Model Loss**: `L_Main` (Cross-Entropy)
- **MTP Module 1 Loss**: `L₁_MTP` (Cross-Entropy)
- **MTP Module 2 Loss**: `L₂_MTP` (Cross-Entropy)
---
## Spatial Grounding
- **Legend**: Not explicitly present (components labeled directly)
- **Color Coding**:
- Beige: Transformer Blocks
- Green: Output Heads & Embedding Layer
- Yellow: Linear Projections & RMSNorm
---
## Trend Verification
- **Token Flow**:
- Input tokens (`t₁-t₄`) → Embedding → Transformer Blocks → Output Heads → Loss
- **Module Progression**:
- Main Model → MTP Module 1 → MTP Module 2 (increasing prediction horizon)
---
## Critical Notes
1. **Shared Components**: Embedding Layer and Output Head are reused across all modules.
2. **Prediction Granularity**:
- Main Model: 1-step prediction
- MTP Modules: Multi-step predictions (2-step and 3-step)
3. **Normalization**: RMSNorm applied after concatenation in MTP modules.
---
## Diagram Structure
```
[Input Tokens] → [Embedding Layer] → [Transformer Blocks] → [Output Head] → [Cross-Entropy Loss]
↓
[MTP Module 1] → [Linear Projection] → [Concatenation] → [RMSNorm] → [Output Head]
↓
[MTP Module 2] → [Linear Projection] → [Concatenation] → [RMSNorm] → [Output Head]
```
---
## Final Output
This architecture enables efficient multi-task learning by sharing core components (Embedding Layer, Output Head) while allowing module-specific adaptations for different prediction horizons. The Cross-Entropy Loss functions optimize each module's task independently.