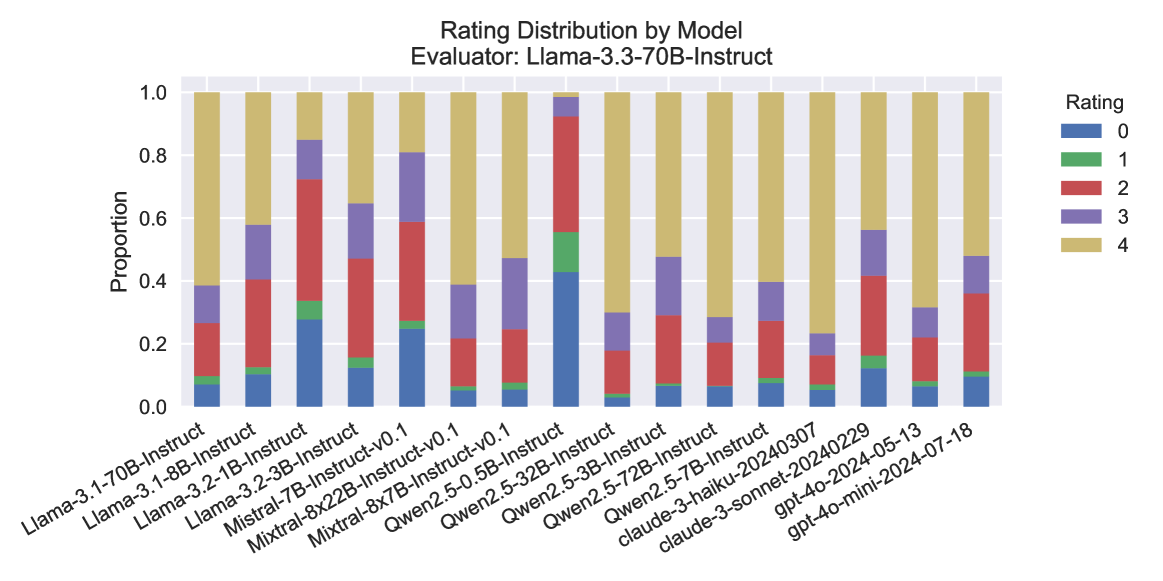
\n
## Stacked Bar Chart: Rating Distribution by Model Evaluator
### Overview
The image presents a stacked bar chart visualizing the rating distribution for various language models, as evaluated by "Llama-3.3-70B-Instruct". The chart displays the proportion of each rating (0 to 4) assigned to each model. The x-axis lists the models, and the y-axis represents the proportion of ratings.
### Components/Axes
* **Title:** "Rating Distribution by Model Evaluator: Llama-3.3-70B-Instruct" (Top-center)
* **X-axis Label:** Model Name (Bottom-center)
* **Y-axis Label:** Proportion (Left-center)
* **Y-axis Scale:** 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner, mapping colors to rating values:
* 0: Blue
* 1: Light Blue
* 2: Pink
* 3: Orange
* 4: Red
* **Models (X-axis):**
* Llama-3.1-70B-Instruct
* Llama-3.1-8B-Instruct
* Llama-3.2-1B-Instruct
* Llama-3.2-3B-Instruct
* Mistral-7B-Instruct
* Mistral-8x22B-Instruct-v0.1
* Mixtral-8x7B-Instruct-v0.1
* Qwen2.5-0.5B-Instruct
* Qwen2.5-32B-Instruct
* Qwen2.5-5B-Instruct
* Qwen2.5-7B-Instruct
* Qwen2.5-72B-Instruct
* claude-3-haiku-20240307
* claude-3-sonnet-2024-05-13
* gpt-4o-mini-2024-07-18
### Detailed Analysis
The chart consists of stacked bars, each representing a model. The height of each segment within a bar indicates the proportion of ratings for that specific value.
* **Llama-3.1-70B-Instruct:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Llama-3.1-8B-Instruct:** Approximately 0.1 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.4 proportion of rating 4.
* **Llama-3.2-1B-Instruct:** Approximately 0.2 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.3 proportion of rating 4.
* **Llama-3.2-3B-Instruct:** Approximately 0.1 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.4 proportion of rating 4.
* **Mistral-7B-Instruct:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Mistral-8x22B-Instruct-v0.1:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Mixtral-8x7B-Instruct-v0.1:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Qwen2.5-0.5B-Instruct:** Approximately 0.2 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.3 proportion of rating 4.
* **Qwen2.5-32B-Instruct:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Qwen2.5-5B-Instruct:** Approximately 0.1 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.4 proportion of rating 4.
* **Qwen2.5-7B-Instruct:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **Qwen2.5-72B-Instruct:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **claude-3-haiku-20240307:** Approximately 0.1 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.4 proportion of rating 4.
* **claude-3-sonnet-2024-05-13:** Approximately 0.05 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.45 proportion of rating 4.
* **gpt-4o-mini-2024-07-18:** Approximately 0.1 proportion of rating 0, 0.1 proportion of rating 1, 0.1 proportion of rating 2, 0.3 proportion of rating 3, and 0.4 proportion of rating 4.
### Key Observations
* Most models receive a high proportion of rating 4, indicating generally positive evaluations.
* The proportion of rating 0 is relatively low across all models.
* There is a slight variation in the distribution of ratings among the models, but the overall pattern is consistent.
* Models like Llama-3.1-70B-Instruct, Mistral-7B-Instruct, Mistral-8x22B-Instruct-v0.1, Mixtral-8x7B-Instruct-v0.1, Qwen2.5-32B-Instruct, Qwen2.5-72B-Instruct, claude-3-sonnet-2024-05-13 appear to have slightly higher proportions of rating 4.
### Interpretation
The chart demonstrates that, according to the Llama-3.3-70B-Instruct evaluator, the majority of the assessed language models perform well, receiving predominantly high ratings (3 and 4). The consistent pattern across models suggests that the evaluator has a relatively high baseline expectation or that the models generally meet a certain performance standard. The small variations in rating distributions could indicate subtle differences in model capabilities or biases in the evaluation process. The relatively low proportion of rating 0 suggests that none of the models are considered entirely unsatisfactory by this evaluator. The data suggests a generally positive landscape for these language models, with most exhibiting strong performance characteristics. Further investigation could explore the specific criteria used by the Llama-3.3-70B-Instruct evaluator to understand the nuances behind the ratings.