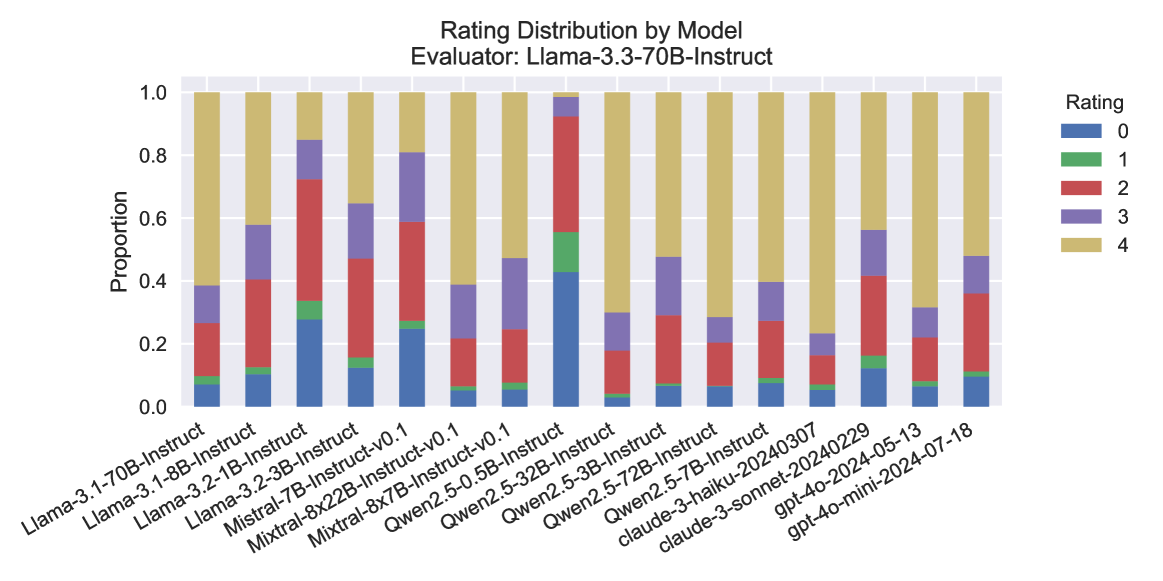
## Bar Chart: Rating Distribution by Model Evaluator: Llama-3.3-70B-Instruct
### Overview
The chart displays the distribution of ratings (0-4) assigned by the Llama-3.3-70B-Instruct model to various AI models. Each bar represents a different model, with colored segments indicating the proportion of ratings received. The y-axis shows the proportion of ratings (0-1), while the x-axis lists model names.
### Components/Axes
- **Title**: "Rating Distribution by Model Evaluator: Llama-3.3-70B-Instruct"
- **X-axis**: Model names (e.g., Llama-3.1-70B-Instruct, Mistral-7B-Instruct-v0.1, Owen2-5-32B-Instruct)
- **Y-axis**: "Proportion" (0-1 in increments of 0.2)
- **Legend**: Located on the right, with colors:
- Blue: Rating 0
- Green: Rating 1
- Red: Rating 2
- Purple: Rating 3
- Yellow: Rating 4
### Detailed Analysis
- **Model Ratings**:
- **Llama-3.1-70B-Instruct**: Small blue (0), green (1), red (2), purple (3), and largest yellow (4) segment.
- **Llama-3.2-70B-Instruct**: Larger red (2) and purple (3) segments, smaller blue (0) and green (1).
- **Mistral-7B-Instruct-v0.1**: Dominant red (2) and purple (3) segments, minimal blue (0).
- **Mistral-8x7B-Instruct-v0.1**: Similar to Mistral-7B but with slightly more yellow (4).
- **Qwen2-5-32B-Instruct**: Largest blue (0) segment, minimal red (2) and purple (3).
- **Claude-3-haiku-20240307**: Balanced distribution across all ratings, with notable yellow (4).
- **GPT-40-mini-2024-05-13**: Moderate blue (0) and yellow (4), with smaller red (2) and purple (3).
### Key Observations
1. **Rating Distribution Variability**: Models exhibit diverse rating distributions. For example:
- **Owen2-5-32B-Instruct** has the highest proportion of rating 0 (blue).
- **Mistral-7B-Instruct-v0.1** has the highest proportion of rating 2 (red).
2. **Color Consistency**: All segments align with the legend (e.g., blue = 0, yellow = 4).
3. **Proportion Trends**:
- Models like **Claude-3-haiku-20240307** and **GPT-40-mini-2024-05-13** show balanced distributions.
- **Llama-3.3-70B-Instruct** (evaluator) has a high proportion of rating 4 (yellow) across most models.
### Interpretation
The chart highlights how the Llama-3.3-70B-Instruct model evaluates other AI models. Models with higher proportions of lower ratings (e.g., blue for 0) may indicate underperformance, while those with more yellow (rating 4) suggest superior performance. The **Owen2-5-32B-Instruct** model stands out with the highest rating 0 proportion, potentially indicating a unique evaluation outcome. Conversely, **Mistral-7B-Instruct-v0.1** and **Mistral-8x7B-Instruct-v0.1** show strong mid-range ratings (2-3), suggesting moderate performance. The evaluator’s own high rating 4 proportion (yellow) across models implies a generally positive assessment framework. This data could reflect differences in model capabilities, training data, or evaluation criteria.