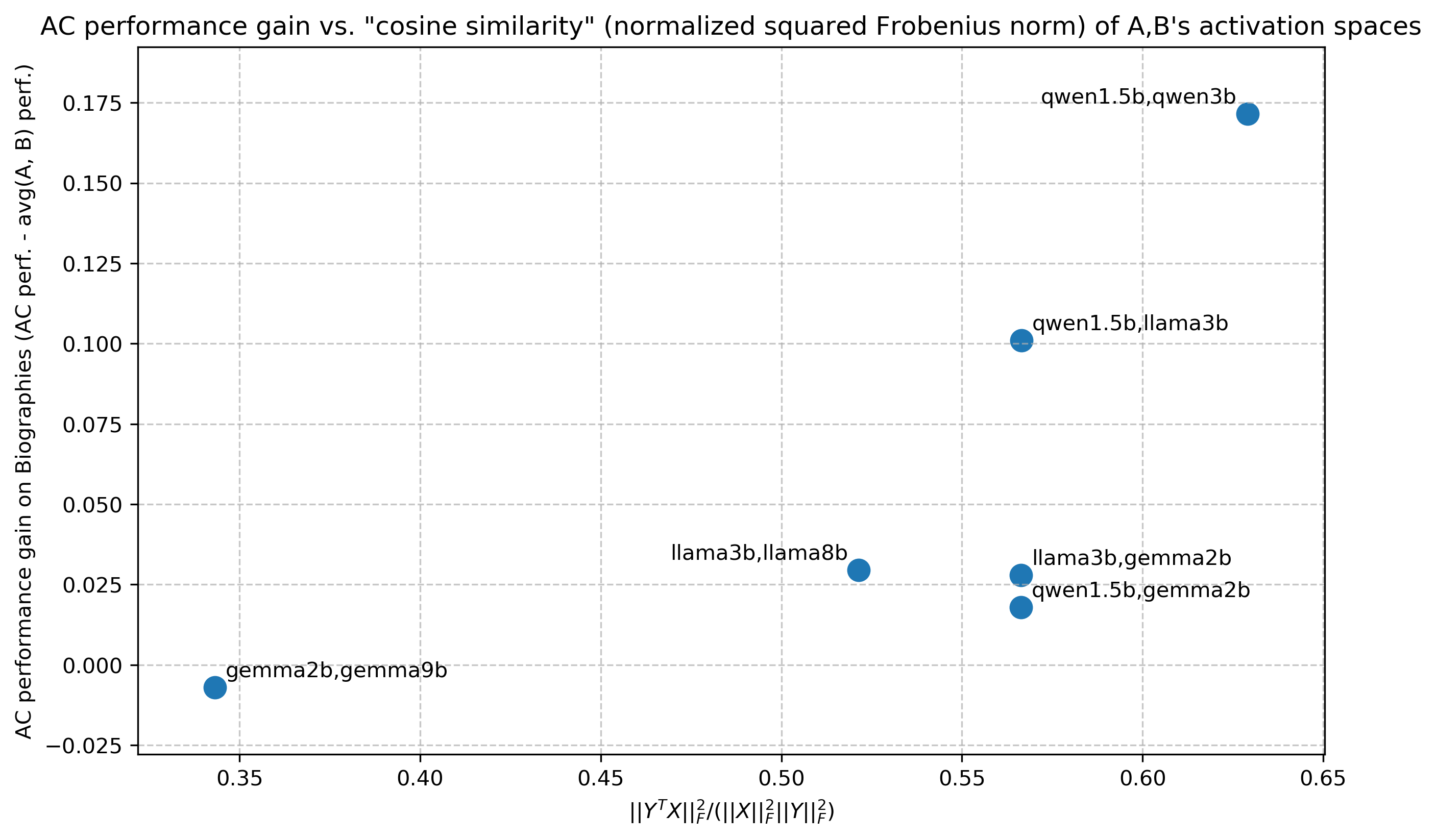
## Scatter Plot: AC Performance Gain vs. Cosine Similarity
### Overview
The image is a scatter plot comparing AC performance gain (on the y-axis) against cosine similarity (normalized squared Frobenius norm of activation spaces) on the x-axis. Data points are labeled with pairs of model names (e.g., "qwen1.5b,qwen3b"), and their positions reflect their respective metric values.
### Components/Axes
- **Title**: "AC performance gain vs. 'cosine similarity' (normalized squared Frobenius norm) of A,B's activation spaces"
- **X-axis**:
- Label: `||Y^T X||_F²/(||X||_F² ||Y||_F²)` (normalized squared Frobenius norm)
- Scale: 0.35 to 0.65 (approximate)
- **Y-axis**:
- Label: "AC performance gain on Biographies (AC perf. - avg(A, B) perf.)"
- Scale: -0.025 to 0.175 (approximate)
- **Data Points**: Blue dots with labels combining model names (e.g., "qwen1.5b,qwen3b"). No explicit legend is present, but all points are blue.
### Detailed Analysis
1. **Data Points**:
- **qwen1.5b,qwen3b**: X ≈ 0.63, Y ≈ 0.17 (top-right corner).
- **qwen1.5b,llama3b**: X ≈ 0.57, Y ≈ 0.10 (upper-middle-right).
- **llama3b,llama8b**: X ≈ 0.52, Y ≈ 0.025 (middle-center).
- **llama3b,gemma2b**: X ≈ 0.57, Y ≈ 0.02 (middle-right).
- **qwen1.5b,gemma2b**: X ≈ 0.57, Y ≈ 0.015 (middle-right, slightly lower than "llama3b,gemma2b").
- **gemma2b,gemma9b**: X ≈ 0.35, Y ≈ -0.01 (bottom-left).
2. **Trends**:
- Higher cosine similarity (x-axis) generally correlates with higher AC performance gain (y-axis), but exceptions exist.
- The highest gain (0.17) occurs at the maximum x-value (0.63), suggesting a strong relationship between similarity and performance for "qwen1.5b,qwen3b".
- Lower gains (e.g., -0.01 for "gemma2b,gemma9b") occur at lower x-values, indicating poorer performance for dissimilar models.
### Key Observations
- **Outlier**: "qwen1.5b,gemma2b" has a high x-value (0.57) but a relatively low y-value (0.015), suggesting that high similarity does not always guarantee high performance.
- **Consistency**: "qwen1.5b" pairs (e.g., with "qwen3b" or "llama3b") consistently show higher gains than "llama3b" or "gemma2b" pairs.
- **Negative Gain**: "gemma2b,gemma9b" is the only point below the zero line, indicating a performance loss compared to the average.
### Interpretation
The data suggests that models with higher cosine similarity in their activation spaces tend to exhibit better AC performance gains. However, the presence of outliers (e.g., "qwen1.5b,gemma2b") implies that similarity alone is not the sole determinant of performance. Architectural differences, training data, or other latent factors may influence results. The negative gain for "gemma2b,gemma9b" highlights cases where dissimilar models underperform, possibly due to conflicting activation patterns. This scatter plot underscores the importance of activation space alignment in model performance but also signals the need for further investigation into confounding variables.