## Scatter Plot: Accuracy on the MATH test set
### Overview
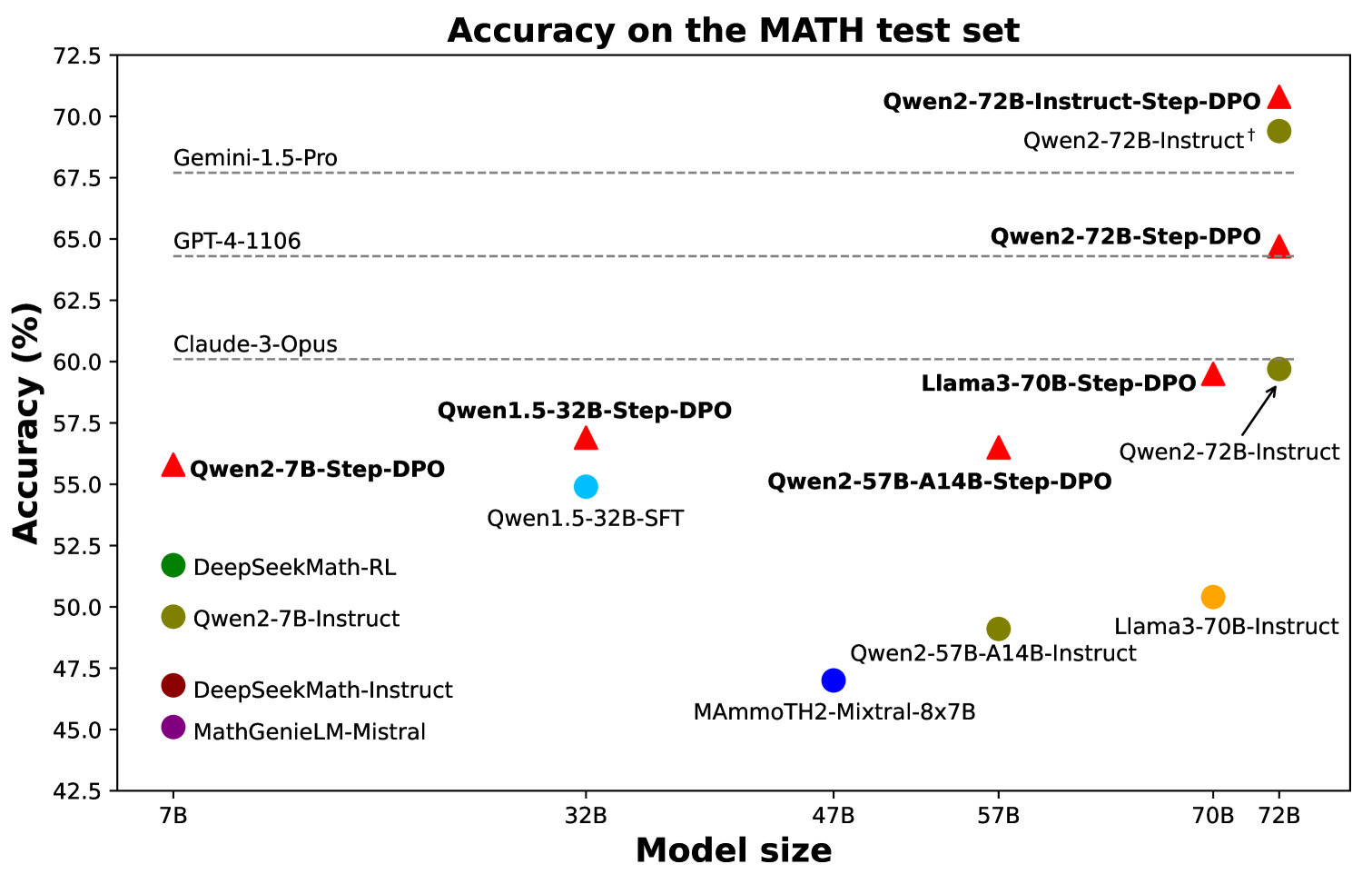
The image is a scatter plot visualizing the accuracy of various AI models on a MATH test set. The x-axis represents model size (in billions of parameters), and the y-axis represents accuracy (in percentage). Data points are color-coded and shaped to distinguish between models and their configurations (e.g., "Step-DPO" vs. "Instruct"). The plot includes labeled data points, a legend, and axis markers.
---
### Components/Axes
- **Title**: "Accuracy on the MATH test set"
- **X-axis**: "Model size" (ranging from 7B to 72B, with markers at 7B, 32B, 47B, 57B, 70B, 72B)
- **Y-axis**: "Accuracy (%)" (ranging from 42.5% to 72.5%, with markers at 42.5%, 45%, 47.5%, 50%, 52.5%, 55%, 57.5%, 60%, 62.5%, 65%, 67.5%, 70%)
- **Legend**:
- **Colors/Symbols**:
- **Red triangle**: Qwen2-7B-Step-DPO, Qwen2-32B-Step-DPO, Qwen2-57B-A14B-Step-DPO, Qwen2-72B-Step-DPO
- **Green circle**: DeepSeekMath-RL, Qwen2-7B-Instruct, Qwen2-72B-Instruct
- **Blue circle**: Qwen1.5-32B-SFT, MAmmoTH2-Mixtral-8x7B
- **Yellow circle**: Llama3-70B-Instruct
- **Purple circle**: MathGenieLM-Mistral
- **Orange circle**: Llama3-70B-Step-DPO
- **Brown circle**: Qwen2-72B-Instruct†
- **Red triangle with black outline**: Qwen2-72B-Instruct-Step-DPO
- **Red triangle with white outline**: Qwen2-72B-Step-DPO
- **Red triangle with black outline and white outline**: Qwen2-72B-Instruct-Step-DPO (duplicate label?)
---
### Detailed Analysis
#### Data Points and Trends
1. **Model Size vs. Accuracy**:
- **Largest models** (70B–72B) generally show higher accuracy:
- **Qwen2-72B-Instruct-Step-DPO** (72B, 70%) is the highest.
- **Qwen2-72B-Instruct** (72B, 69%) follows closely.
- **Llama3-70B-Step-DPO** (70B, 60%) and **Llama3-70B-Instruct** (70B, 50%) are lower but still among the top.
- **Mid-sized models** (32B–57B):
- **Qwen2-32B-Step-DPO** (32B, 58%) and **Qwen2-57B-A14B-Step-DPO** (57B, 57%) show moderate accuracy.
- **Qwen1.5-32B-SFT** (32B, 54%) and **MAmmoTH2-Mixtral-8x7B** (47B, 47%) are lower.
- **Smallest models** (7B):
- **Qwen2-7B-Step-DPO** (7B, 55%) and **DeepSeekMath-Instruct** (7B, 45%) are the lowest.
2. **Step-DPO vs. Instruct**:
- **Step-DPO** (red triangles) generally outperforms **Instruct** (green circles) across similar model sizes:
- Qwen2-72B-Step-DPO (65%) > Qwen2-72B-Instruct (69%).
- Qwen2-57B-A14B-Step-DPO (57%) > Qwen2-57B-A14B-Instruct (49%).
- Exceptions:
- **Gemini-1.5-Pro** (68%) and **GPT-4-1106** (65%) are high-performing but not labeled with Step-DPO.
3. **Notable Outliers**:
- **MathGenieLM-Mistral** (45%) is the lowest accuracy.
- **Qwen2-72B-Instruct†** (69%) is the second-highest accuracy but lacks a Step-DPO label.
---
### Key Observations
1. **Model Size Correlation**:
- Larger models (70B–72B) dominate the top accuracy range (65%–70%).
- Smaller models (7B–32B) cluster below 60%, with Step-DPO configurations showing marginal improvements.
2. **Step-DPO Effectiveness**:
- Step-DPO (red triangles) consistently outperforms Instruct (green circles) for the same model size (e.g., Qwen2-72B-Step-DPO vs. Qwen2-72B-Instruct).
3. **Exceptions**:
- **Gemini-1.5-Pro** (68%) and **GPT-4-1106** (65%) achieve high accuracy without Step-DPO, suggesting alternative architectures or training methods.
4. **Llama3 Variants**:
- Llama3-70B-Step-DPO (60%) outperforms Llama3-70B-Instruct (50%), but both lag behind Qwen2 models.
---
### Interpretation
The data demonstrates a **positive correlation between model size and accuracy**, with larger models (70B–72B) achieving the highest performance. The **Step-DPO method** (red triangles) consistently improves accuracy compared to standard Instruct configurations (green circles) for the same model size. However, exceptions like **Gemini-1.5-Pro** and **GPT-4-1106** suggest that architectural innovations or specialized training data can also drive high performance. The **Qwen2-72B-Instruct-Step-DPO** (70%) stands out as the most accurate model, while **MathGenieLM-Mistral** (45%) highlights the limitations of smaller, less optimized models. The plot underscores the importance of both model scale and training methodology in achieving high accuracy on mathematical tasks.