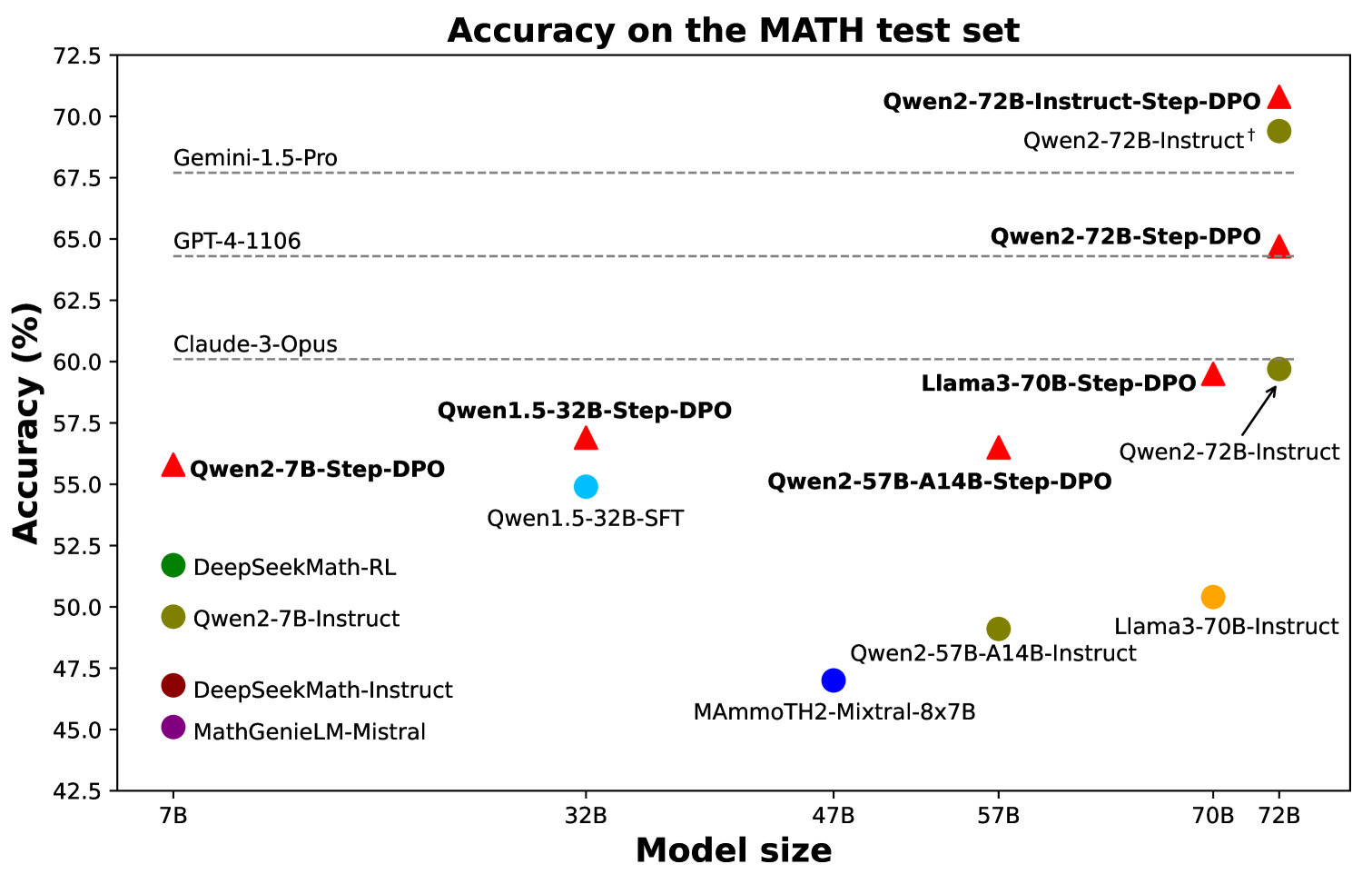
## Scatter Plot: Accuracy on the MATH test set
### Overview
This scatter plot visualizes the accuracy of various language models on the MATH test set, plotted against their model size. The accuracy is measured in percentage (%), and the model size is measured in billions of parameters (B). Different models are represented by different colored markers (red triangles, green circles, and black squares).
### Components/Axes
* **Title:** Accuracy on the MATH test set
* **X-axis:** Model size (B). Scale ranges from approximately 5B to 75B. Markers are placed at 7B, 32B, 47B, 57B, 70B, and 72B.
* **Y-axis:** Accuracy (%). Scale ranges from approximately 42% to 72.5%. Markers are placed at 42.5%, 45%, 47.5%, 50%, 52.5%, 55%, 57.5%, 60%, 62.5%, 65%, 67.5%, 70%, and 72.5%.
* **Legend:** Implicitly defined by marker shape and color.
* Red Triangles: Models ending in "-DPO"
* Green Circles: Models ending in "-Instruct" or "-Instruct-SFT"
* Black Squares: Models without "-DPO" or "-Instruct" in their name.
### Detailed Analysis
The plot shows a general trend of increasing accuracy with increasing model size, but with significant variation between models.
* **Gemini-1.5-Pro:** Approximately 70.0% accuracy at 72B. (Red Triangle)
* **Qwen2-72B-Instruct-Step-DPO:** Approximately 70.5% accuracy at 72B. (Red Triangle)
* **Qwen2-72B-Instruct:** Approximately 69.5% accuracy at 72B. (Red Triangle)
* **Qwen2-72B-Step-DPO:** Approximately 68.5% accuracy at 72B. (Red Triangle)
* **GPT-4-1106:** Approximately 65.0% accuracy at 72B. (Red Triangle)
* **Claude-3-Opus:** Approximately 60.0% accuracy at 72B. (Red Triangle)
* **Llama3-70B-DPO:** Approximately 58.0% accuracy at 70B. (Red Triangle)
* **Qwen2-57B-A14B-Step-DPO:** Approximately 57.5% accuracy at 57B. (Red Triangle)
* **Qwen2-57B-A14B-Instruct:** Approximately 50.0% accuracy at 57B. (Green Circle)
* **Qwen2-32B-Step-DPO:** Approximately 57.5% accuracy at 32B. (Red Triangle)
* **Qwen1.5-32B-SFT:** Approximately 52.5% accuracy at 32B. (Green Circle)
* **Qwen2-7B-Step-DPO:** Approximately 55.0% accuracy at 7B. (Red Triangle)
* **Qwen2-7B-Instruct:** Approximately 50.0% accuracy at 7B. (Green Circle)
* **DeepSeekMath-RL:** Approximately 52.5% accuracy at 7B. (Green Circle)
* **DeepSeekMath-Instruct:** Approximately 47.5% accuracy at 7B. (Green Circle)
* **MathGenieLM-Mistral:** Approximately 45.0% accuracy at 7B. (Green Circle)
* **MAmmoTH2-Mixtral-8x7B:** Approximately 47.5% accuracy at 47B. (Black Square)
* **Llama3-70B-Instruct:** Approximately 50.0% accuracy at 70B. (Green Circle)
### Key Observations
* Models with "-DPO" in their name (red triangles) generally exhibit higher accuracy than those without, especially at larger model sizes.
* Qwen2-72B-Instruct-Step-DPO achieves the highest accuracy among the models shown.
* There's a noticeable gap in accuracy between models around the 32B and 57B size ranges.
* The models ending in "-Instruct" (green circles) show a relatively consistent accuracy across different model sizes.
* MAmmoTH2-Mixtral-8x7B is an outlier, showing lower accuracy than other models of similar size.
### Interpretation
The data suggests that model size is a significant factor in achieving higher accuracy on the MATH test set, but it is not the only one. The training methodology, as indicated by the "-DPO" suffix, appears to play a crucial role. Models trained with Direct Preference Optimization (DPO) consistently outperform others. The variation in accuracy among models of similar size highlights the importance of architectural choices and training data. The outlier, MAmmoTH2-Mixtral-8x7B, may indicate that its architecture or training process is less effective for this specific task. The plot demonstrates the ongoing progress in language model development, with newer models like Gemini-1.5-Pro and Qwen2-72B-Instruct-Step-DPO achieving state-of-the-art results. The consistent performance of the "-Instruct" models suggests that instruction tuning is a valuable technique for improving performance on tasks requiring following instructions.