\n
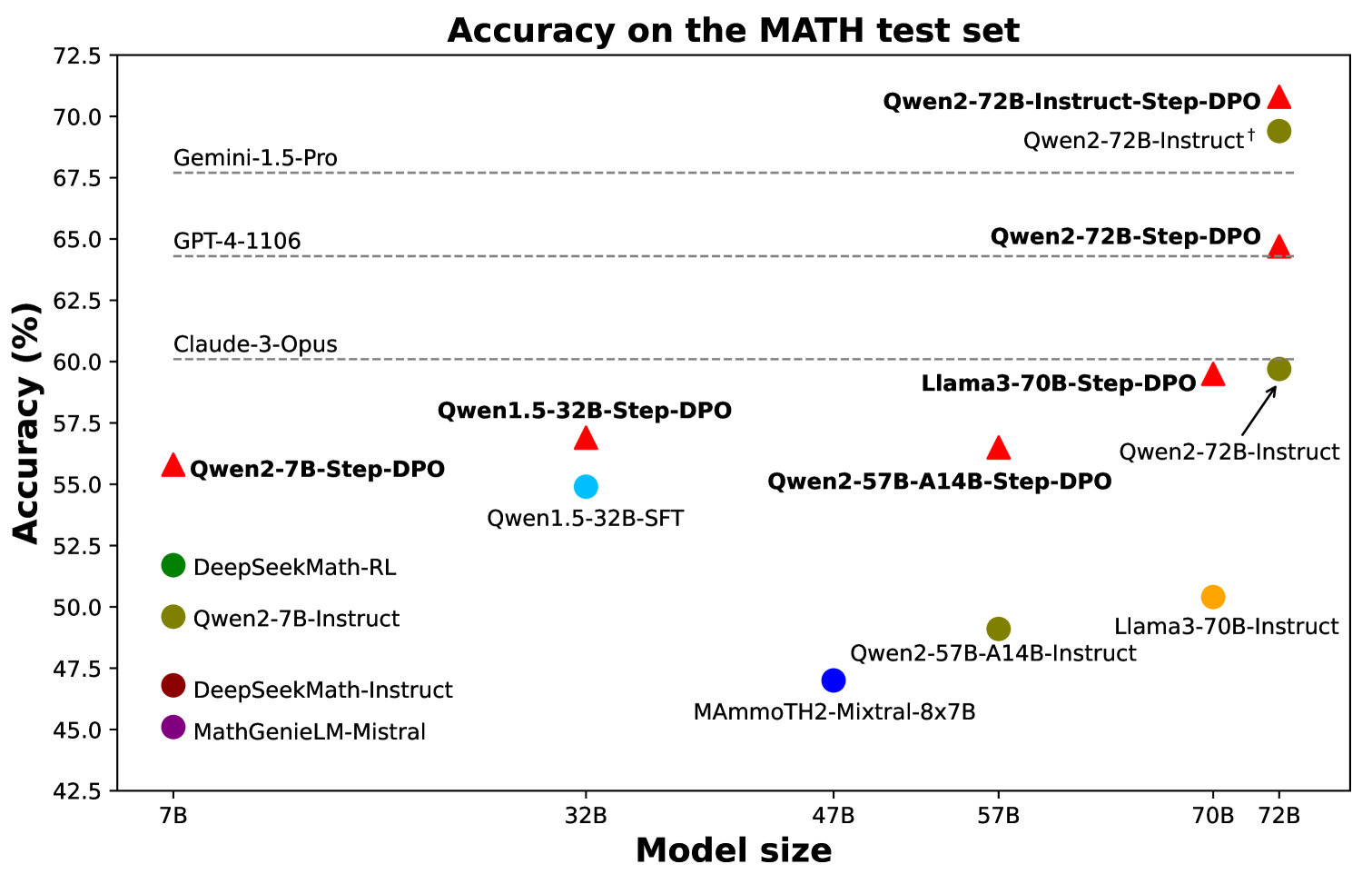
## Scatter Plot: Accuracy on the MATH test set
### Overview
This is a scatter plot comparing the accuracy of various large language models (LLMs) on the MATH test set, plotted against their model size (parameter count). The chart highlights the performance of models from the Qwen family, particularly those using "Step-DPO" fine-tuning, against other prominent models and baselines.
### Components/Axes
* **Chart Title:** "Accuracy on the MATH test set" (centered at the top).
* **Y-Axis:** Labeled "Accuracy (%)". Scale ranges from 42.5 to 72.5, with major ticks every 2.5 units (42.5, 45.0, 47.5, ..., 72.5).
* **X-Axis:** Labeled "Model size". It is a categorical axis with the following discrete labels from left to right: "7B", "32B", "47B", "57B", "70B", "72B".
* **Legend (Left side, vertically aligned):**
* Green circle: `DeepSeekMath-RL`
* Olive circle: `Qwen2-7B-Instruct`
* Dark red circle: `DeepSeekMath-Instruct`
* Purple circle: `MathGenieLM-Mistral`
* **Reference Baselines (Horizontal dashed lines with labels on the left):**
* `Gemini-1.5-Pro` at approximately 68.0% accuracy.
* `GPT-4-1106` at approximately 64.5% accuracy.
* `Claude-3-Opus` at approximately 60.0% accuracy.
### Detailed Analysis
**Data Points (Approximate values, identified by marker shape/color and label):**
* **7B Size:**
* Red Triangle: `Qwen2-7B-Step-DPO` at ~56.0%.
* **32B Size:**
* Red Triangle: `Qwen1.5-32B-Step-DPO` at ~57.0%.
* Cyan Circle: `Qwen1.5-32B-SFT` at ~55.0%.
* **47B Size:**
* Blue Circle: `MAmmoTH2-Mixtral-8x7B` at ~47.0%.
* **57B Size:**
* Red Triangle: `Qwen2-57B-A14B-Step-DPO` at ~56.5%.
* Olive Circle: `Qwen2-57B-A14B-Instruct` at ~49.0%.
* **70B Size:**
* Red Triangle: `Llama3-70B-Step-DPO` at ~59.5%.
* Orange Circle: `Llama3-70B-Instruct` at ~50.5%.
* **72B Size:**
* Red Triangle: `Qwen2-72B-Step-DPO` at ~65.0%.
* Olive Circle (with dagger †): `Qwen2-72B-Instruct†` at ~69.5%.
* Olive Circle (with arrow): `Qwen2-72B-Instruct` at ~59.5%.
### Key Observations
1. **Step-DPO Performance Trend:** Models labeled with "Step-DPO" (red triangles) consistently outperform their corresponding "Instruct" or "SFT" base models at the same parameter size. This is visible at 32B, 57B, 70B, and 72B.
2. **Scale vs. Accuracy:** For the Qwen2 Step-DPO series (red triangles), there is a clear positive correlation between model size and accuracy, rising from ~56% at 7B to ~65% at 72B.
3. **Top Performers:** The highest accuracy points on the chart are the Qwen2-72B variants. `Qwen2-72B-Instruct†` (~69.5%) surpasses the `Gemini-1.5-Pro` baseline. `Qwen2-72B-Step-DPO` (~65.0%) surpasses the `GPT-4-1106` baseline.
4. **Architectural Outlier:** `MAmmoTH2-Mixtral-8x7B` (blue circle at 47B) has significantly lower accuracy (~47%) compared to other models in a similar size range, suggesting different training or architecture.
5. **Llama3 Comparison:** At 70B, `Llama3-70B-Step-DPO` (~59.5%) shows a substantial improvement over `Llama3-70B-Instruct` (~50.5%), mirroring the Step-DPO benefit seen in Qwen models.
### Interpretation
The data demonstrates the effectiveness of the "Step-DPO" fine-tuning technique for improving mathematical reasoning performance in LLMs. Across multiple model families (Qwen, Llama) and sizes, Step-DPO yields a consistent and often significant accuracy boost over standard instruction-tuned (Instruct) or supervised fine-tuned (SFT) versions.
The plot suggests that while base model scale is a primary driver of performance (the upward trend of red triangles), advanced alignment techniques like Step-DPO can provide a critical performance leap, allowing smaller Step-DPO models to rival or exceed larger, differently tuned models. For instance, the 72B Step-DPO model outperforms the much larger reference baseline `GPT-4-1106`.
The presence of two `Qwen2-72B-Instruct` points (one with a dagger † at ~69.5% and one at ~59.5%) implies a potential variant or different evaluation condition for the same base model, with the dagger version performing exceptionally well, even surpassing the Gemini baseline. This highlights that model performance is not solely a function of size and tuning method, but also of specific implementation details or training checkpoints.
**Language Note:** All text in the image is in English.