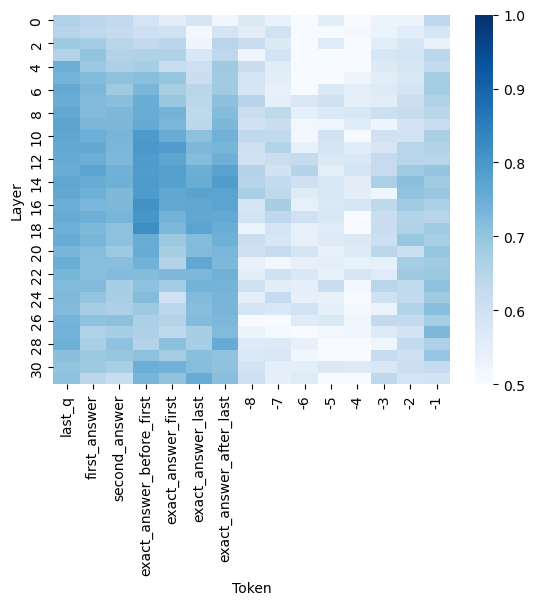
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" (y-axis) and "Token" (x-axis). The color intensity represents a value, with darker blue indicating higher values and lighter blue indicating lower values. The color scale ranges from 0.5 to 1.0.
### Components/Axes
* **Y-axis:** "Layer" with numerical labels from 0 to 30, incrementing by 2.
* **X-axis:** "Token" with categorical labels: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last", "-8", "-7", "-6", "-5", "-4", "-3", "-2", "-1".
* **Color Scale:** Ranges from 0.5 (lightest blue) to 1.0 (darkest blue), with intermediate values of 0.6, 0.7, 0.8, and 0.9. The color scale is positioned on the right side of the heatmap.
### Detailed Analysis
The heatmap shows the values for each combination of layer and token.
* **Tokens "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last":**
* Layers 0-16: Generally have higher values (darker blue), mostly between 0.8 and 1.0.
* Layers 18-30: Values tend to decrease (lighter blue), ranging from 0.6 to 0.8.
* **Tokens "-8" to "-1":**
* Values are generally lower (lighter blue) compared to the other tokens, mostly between 0.5 and 0.7.
* There are some exceptions, such as layer 26 for token "-8", which has a slightly higher value (around 0.7-0.8).
### Key Observations
* The first seven tokens ("last\_q" to "exact\_answer\_after\_last") show a similar pattern: higher values in the lower layers (0-16) and decreasing values in the higher layers (18-30).
* The last eight tokens ("-8" to "-1") have consistently lower values across all layers.
* There is a clear distinction in the heatmap between the first group of tokens and the second group of tokens.
### Interpretation
The heatmap suggests that the initial layers (0-16) of the model are more sensitive to the first seven tokens ("last\_q" to "exact\_answer\_after\_last"), while the later layers (18-30) are less sensitive. The tokens "-8" to "-1" appear to have a consistently lower impact across all layers. This could indicate that the first set of tokens are more important for the model's initial processing, while the second set of tokens might represent less relevant or more nuanced information that is processed differently across the layers. The data suggests a hierarchical processing of information within the model, where different layers focus on different aspects of the input.