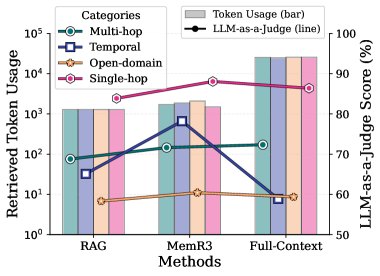
## Chart: Retrieved Token Usage vs. LLM-as-a-Judge Score
### Overview
The image is a combination bar and line chart comparing retrieved token usage and LLM-as-a-Judge score across three methods: RAG, MemR3, and Full-Context. The chart displays token usage for four categories (Multi-hop, Temporal, Open-domain, and Single-hop) as bars, and the LLM-as-a-Judge score as a line.
### Components/Axes
* **X-axis:** Methods (RAG, MemR3, Full-Context)
* **Left Y-axis:** Retrieved Token Usage (logarithmic scale from 10^0 to 10^5)
* **Right Y-axis:** LLM-as-a-Judge Score (%) (linear scale from 50 to 100)
* **Legend (top-left):**
* Multi-hop (teal circle)
* Temporal (dark blue square)
* Open-domain (light orange star)
* Single-hop (magenta circle)
* Token Usage (gray bar)
* LLM-as-a-Judge (black circle)
### Detailed Analysis
**Token Usage (Bars):**
* **RAG:**
* Multi-hop: Approximately 1000
* Temporal: Approximately 50
* Open-domain: Approximately 10
* Single-hop: Approximately 1000
* **MemR3:**
* Multi-hop: Approximately 1500
* Temporal: Approximately 500
* Open-domain: Approximately 15
* Single-hop: Approximately 2000
* **Full-Context:**
* Multi-hop: Approximately 15000
* Temporal: Approximately 15000
* Open-domain: Approximately 15000
* Single-hop: Approximately 15000
**LLM-as-a-Judge Score (Line):**
* **RAG:** Approximately 70%
* **MemR3:** Approximately 90%
* **Full-Context:** Approximately 85%
### Key Observations
* Full-Context method has significantly higher token usage across all categories compared to RAG and MemR3.
* MemR3 achieves the highest LLM-as-a-Judge score, followed by Full-Context, and then RAG.
* Open-domain token usage is consistently the lowest across all methods.
* The LLM-as-a-Judge score decreases from MemR3 to Full-Context, despite the significant increase in token usage.
### Interpretation
The chart suggests that while increasing token usage (as seen in Full-Context) can improve performance compared to RAG, it doesn't necessarily guarantee the best LLM-as-a-Judge score. MemR3 seems to strike a better balance between token usage and performance, achieving the highest score with a lower token usage than Full-Context. This could indicate that MemR3 is more efficient in utilizing the retrieved tokens or that the quality of the retrieved tokens is higher. The low token usage for Open-domain across all methods might suggest that this category requires less information or is inherently simpler to process. The drop in LLM-as-a-Judge score from MemR3 to Full-Context, despite the increase in token usage, could indicate diminishing returns or even the introduction of irrelevant information that negatively impacts the judge's assessment.