\n
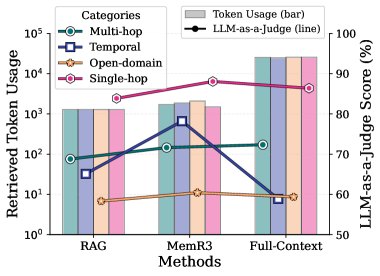
## Chart: Retrieved Token Usage vs. LLM-as-a-Judge Score
### Overview
The image presents a combined bar and line chart comparing the retrieved token usage and LLM-as-a-judge score for three different methods: RAG, MemR3, and Full-Context. The chart visualizes how token usage varies across different categories (Multi-hop, Temporal, Open-domain, Single-hop) and how these relate to the LLM-as-a-judge score. The Y-axis on the left represents Retrieved Token Usage on a logarithmic scale, while the Y-axis on the right represents the LLM-as-a-Judge Score in percentage.
### Components/Axes
* **X-axis:** Methods - RAG, MemR3, Full-Context.
* **Left Y-axis:** Retrieved Token Usage (Logarithmic Scale). Ranges from 10⁰ (1) to 10⁵ (100,000).
* **Right Y-axis:** LLM-as-a-Judge Score (%). Ranges from 50% to 100%.
* **Legend (Top-Right):**
* Multi-hop (Teal Circle)
* Temporal (Blue Square)
* Open-domain (Orange Star)
* Single-hop (Pink Diamond)
* LLM-as-a-Judge (Black Line)
* **Bars:** Represent Retrieved Token Usage for each category and method. The bars are colored according to the categories.
* **Lines:** Represent LLM-as-a-Judge Score for each method.
### Detailed Analysis
The chart displays the following data:
**RAG (Retrieval-Augmented Generation):**
* Multi-hop: Retrieved Token Usage ≈ 75, LLM-as-a-Judge Score ≈ 72%
* Temporal: Retrieved Token Usage ≈ 250, LLM-as-a-Judge Score ≈ 78%
* Open-domain: Retrieved Token Usage ≈ 10, LLM-as-a-Judge Score ≈ 60%
* Single-hop: Retrieved Token Usage ≈ 1000, LLM-as-a-Judge Score ≈ 88%
* LLM-as-a-Judge (overall): ≈ 75%
**MemR3:**
* Multi-hop: Retrieved Token Usage ≈ 150, LLM-as-a-Judge Score ≈ 82%
* Temporal: Retrieved Token Usage ≈ 800, LLM-as-a-Judge Score ≈ 85%
* Open-domain: Retrieved Token Usage ≈ 10, LLM-as-a-Judge Score ≈ 62%
* Single-hop: Retrieved Token Usage ≈ 1200, LLM-as-a-Judge Score ≈ 92%
* LLM-as-a-Judge (overall): ≈ 85%
**Full-Context:**
* Multi-hop: Retrieved Token Usage ≈ 120, LLM-as-a-Judge Score ≈ 75%
* Temporal: Retrieved Token Usage ≈ 500, LLM-as-a-Judge Score ≈ 80%
* Open-domain: Retrieved Token Usage ≈ 8, LLM-as-a-Judge Score ≈ 58%
* Single-hop: Retrieved Token Usage ≈ 1000, LLM-as-a-Judge Score ≈ 90%
* LLM-as-a-Judge (overall): ≈ 82%
**Trends:**
* **LLM-as-a-Judge Line:** The black line representing the LLM-as-a-Judge score generally slopes upward from RAG to MemR3, then slightly decreases towards Full-Context.
* **Single-hop:** Consistently shows the highest token usage across all methods.
* **Open-domain:** Consistently shows the lowest token usage across all methods.
### Key Observations
* MemR3 consistently achieves the highest LLM-as-a-Judge scores.
* Single-hop queries require the most tokens across all methods.
* Open-domain queries require the fewest tokens.
* There's a general trend of increasing LLM-as-a-Judge score with increasing token usage, but this isn't strictly linear. The relationship appears to plateau or even decrease slightly for Full-Context.
### Interpretation
The chart suggests that MemR3 is the most effective method for balancing token usage and LLM-as-a-Judge score. While higher token usage doesn't always guarantee a higher score, it generally correlates positively, especially when comparing RAG and MemR3. The Full-Context method shows a slight decrease in LLM-as-a-Judge score despite comparable token usage to MemR3, indicating that simply providing more context isn't always beneficial.
The differences in token usage across categories highlight the varying complexity of different query types. Single-hop queries, likely requiring less information retrieval, use the most tokens, while Open-domain queries, potentially benefiting from broader context, use the least. This could be due to the retrieval mechanisms prioritizing more information for simpler queries or the nature of the data itself.
The logarithmic scale on the Y-axis for token usage is crucial. It emphasizes the significant differences in token usage between categories like Open-domain and Single-hop. The LLM-as-a-Judge score provides a metric for evaluating the quality of the retrieved information, suggesting that the methods are not only retrieving tokens but also retrieving *relevant* tokens. The plateauing effect observed with Full-Context suggests a point of diminishing returns – adding more context beyond a certain threshold doesn't necessarily improve the LLM's judgment.